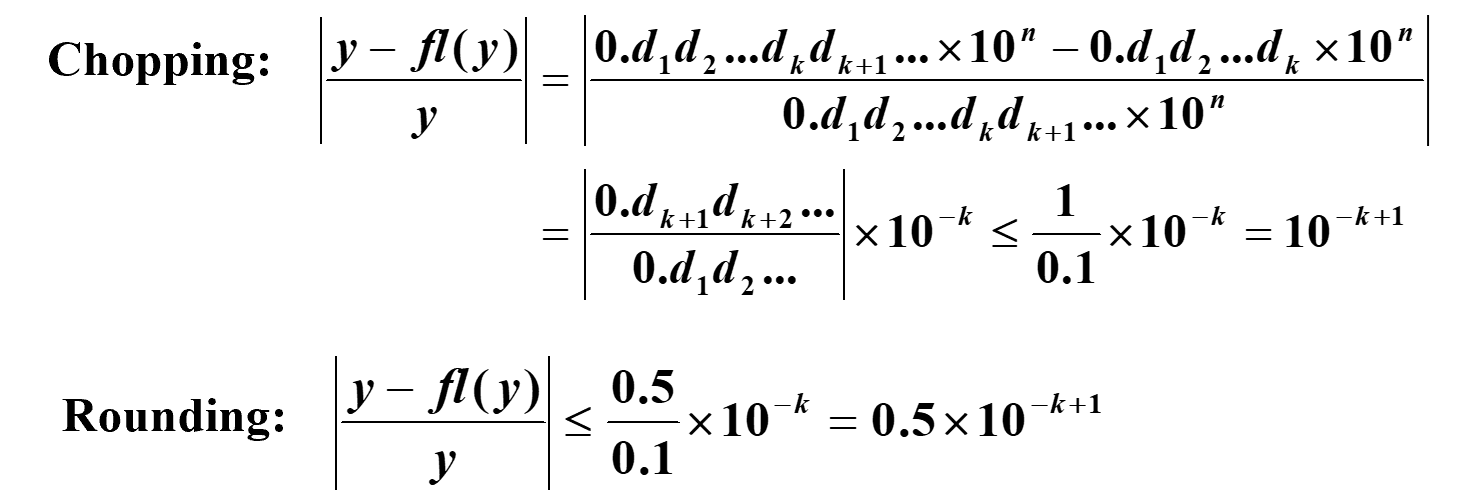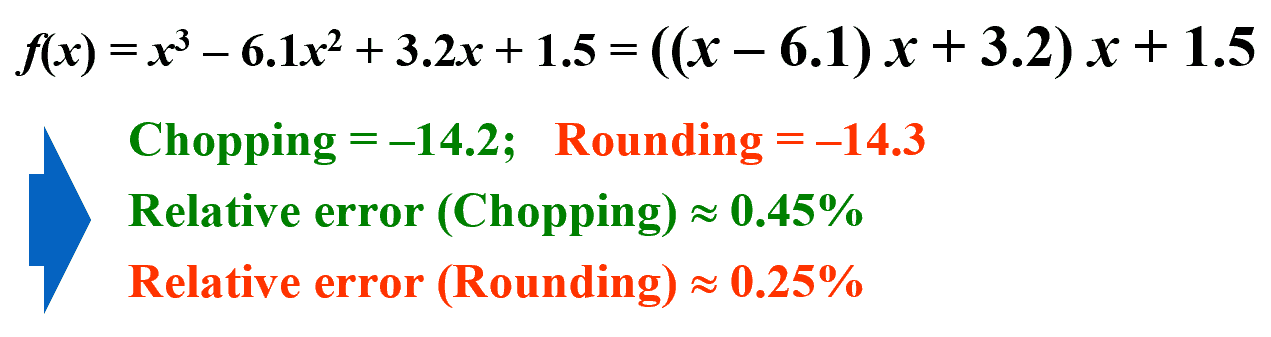Copyright
数值分析课程的相关笔记在 Jiepeng 大佬的笔记 的基础之上修改而来,欢迎大家支持原作者。
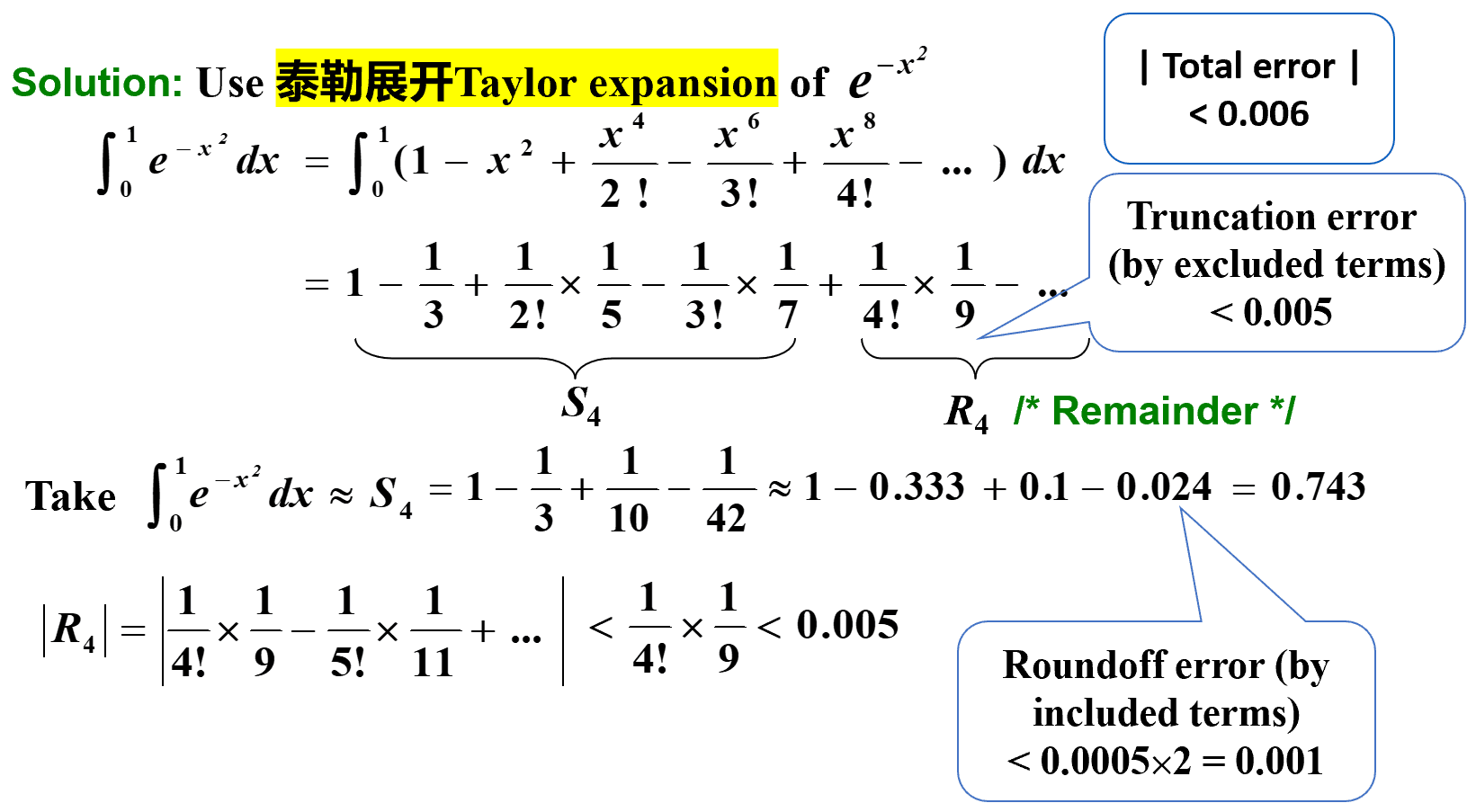
截断误差(truncation error) : 使用截断的(或者说有限的)求和来近似无穷级数的和产生的误差。
理论:e = ∑ n = 0 ∞ 1 n ! e=\sum\limits_{n=0}^{\infty} \frac{1}{n!} e = n = 0 ∑ ∞ n ! 1
计算机: e = ∑ n = 0 N 1 n ! e=\sum\limits_{n=0}^{N} \frac{1}{n!} e = n = 0 ∑ N n ! 1
舍入误差(roundoff error) : 当计算机执行实数计算时产生的误差。这是因为计算机中的算术运算涉及到的数字只有有限位数。
理论:0.3333333 ⋯ 0.3333333\cdots 0.3333333 ⋯
计算机: 0.333333 0.333333 0.333333
Discussion 1: 估计 ∫ 0 1 e − x 2 d x \displaystyle{\int_{0}^{1} e^{-x^{2}} \text{d} x} ∫ 0 1 e − x 2 d x
使用截断法或舍入法产生的误差都叫做 舍入误差(roundoff error) 。
截断法(chopping) :0.1119 -> 0.111舍入法(rounding) :0.1119 -> 0.112
给定一个 实数的标准十进制浮点形式(normalized decimal floating-point form of a real number) y = 0. d 1 d 2 d 3 … d k d k + 1 … × 1 0 n y = 0.d_1d_2d_3\ldots d_kd_{k+1}\ldots \times 10^n y = 0. d 1 d 2 d 3 … d k d k + 1 … × 1 0 n
f l ( y ) = { 0. d 1 d 2 d 3 … d k × 1 0 n /* chopping */ c h o p ( y + 5 × 1 0 n − ( k + 1 ) ) /* rounding */ fl(y) = \begin{cases} 0.d_1d_2d_3\ldots d_k \times 10^n& \text{/* chopping */} \\ chop(y + 5 \times 10^{n-(k+1)}) & \text{/* rounding */} \end{cases} f l ( y ) = { 0. d 1 d 2 d 3 … d k × 1 0 n c h o p ( y + 5 × 1 0 n − ( k + 1 ) ) /* chopping */ /* rounding */ 用 p ∗ p^* p ∗ p p p 近似值(approximation) 。
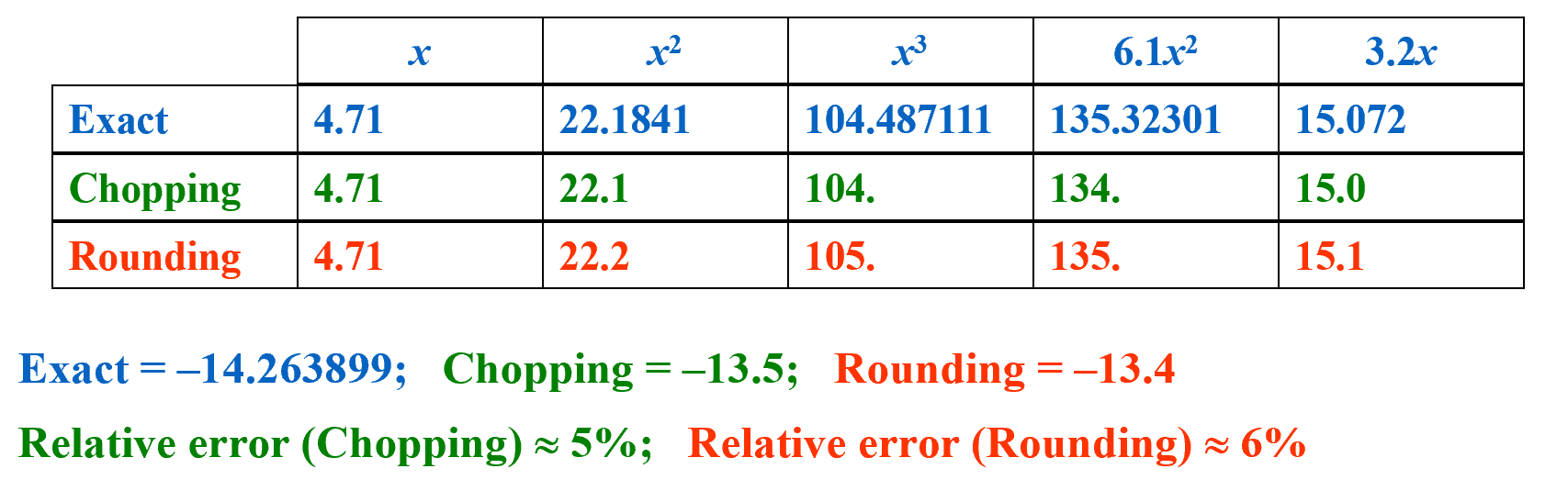
绝对误差(absolute error) :∣ p ∗ − p ∣ |p^* - p| ∣ p ∗ − p ∣ 相对误差(relative error) :∣ p ∗ − p ∣ ∣ p ∣ \dfrac{|p^* - p|}{|p|} ∣ p ∣ ∣ p ∗ − p ∣
有效位(significant digit / significant figure) :对于 p p p p ∗ p^\ast p ∗ ∣ p ∗ − p ∣ ∣ p ∣ < 5 × 1 0 − t \displaystyle{\dfrac{|p^* - p|}{|p|}<5 \times 10^{-t}} ∣ p ∣ ∣ p ∗ − p ∣ < 5 × 1 0 − t p ∗ p^{\ast} p ∗ t t t
近似产生的误差
舍入误差如何影响我们的结果?
相近数相减导致有效位数减少。
除以小数或乘以大数导致误差放大。
建议:先简化再输入到计算机。
误差产生
两个近乎相等的数相减导致有效数字的相消,例如:a = 0.123456789 , b = 0.123456788 a=0.123456789, b=0.123456788 a = 0.123456789 , b = 0.123456788
如果有限位的表示或计算产生了误差,则除以一个小数(或者乘以一个大数)会放大绝对误差。
Discussion 2: Evaluate f ( x ) = x 3 − 6.1 x 2 + 3.2 x + 1.5 f(x)=x^{3}-6.1x^{2}+3.2x+1.5 f ( x ) = x 3 − 6.1 x 2 + 3.2 x + 1.5 x = 4.71 x=4.71 x = 4.71
注意这里第二行第四列的 134. 134. 134. 104. 104. 104. 4.71 4.71 4.71 135.32301 135.32301 135.32301
乘法较多会导致式子的误差较大,秦九韶算法(Horner’s Method) 通过不断提取 x x x f ( x ) = a n x n + a n − 1 x n − 1 + … + a 1 x + a 0 f(x) = a_nx^n + a_{n-1}x^{n-1} + \ldots + a_1x + a_0 f ( x ) = a n x n + a n − 1 x n − 1 + … + a 1 x + a 0
f ( x ) = ( ( … ( a n x + a n − 1 ) x + a n − 2 ) x + … ) x + a 1 ) x + a 0 f(x) = ((\ldots(a_nx + a_{n-1})x + a_{n-2})x + \ldots)x + a_1)x + a_0 f ( x ) = (( … ( a n x + a n − 1 ) x + a n − 2 ) x + … ) x + a 1 ) x + a 0 然后从最内层开始计算。
Discussion 2 (with Horner's Method)
Chopping :( ( 4.71 − 6.1 ) 4.71 + 3.2 ) 4.71 + 1.5 = ( − 1.39 ∗ 4.71 + 3.2 ) 4.71 + 1.5 = ( − 6.54 + 3.2 ) 4.71 + 1.5 = − 3.34 ∗ 4.71 + 1.5 = − 15.7 + 1.5 = − 14.2 \begin{aligned}&((4.71-6.1)4.71 + 3.2)4.71 + 1.5 \\=& (-1.39*4.71 + 3.2)4.71 + 1.5 \\=& (-6.54 + 3.2)4.71 + 1.5 \\=& -3.34*4.71 + 1.5 \\=& -15.7 + 1.5 \\=& -14.2\end{aligned} = = = = = (( 4.71 − 6.1 ) 4.71 + 3.2 ) 4.71 + 1.5 ( − 1.39 ∗ 4.71 + 3.2 ) 4.71 + 1.5 ( − 6.54 + 3.2 ) 4.71 + 1.5 − 3.34 ∗ 4.71 + 1.5 − 15.7 + 1.5 − 14.2
Relative error: ∣ − 14.263899 + 14.2 ∣ ∣ − 14.263899 ∣ ≈ 0.44 % \frac{|-14.263899 + 14.2|}{|-14.263899|} \approx 0.44\% ∣ − 14.263899∣ ∣ − 14.263899 + 14.2∣ ≈ 0.44%
Rounding :( ( 4.71 − 6.1 ) 4.71 + 3.2 ) 4.71 + 1.5 = ( − 1.39 ∗ 4.71 + 3.2 ) 4.71 + 1.5 = ( − 6.55 + 3.2 ) 4.71 + 1.5 = − 3.35 ∗ 4.71 + 1.5 = − 15.8 + 1.5 = − 14.3 \begin{aligned}&((4.71-6.1)4.71 + 3.2)4.71 + 1.5 \\=& (-1.39*4.71 + 3.2)4.71 + 1.5 \\=& (-6.55 + 3.2)4.71 + 1.5 \\=& -3.35*4.71 + 1.5 \\=& -15.8 + 1.5 \\=& -14.3\end{aligned} = = = = = (( 4.71 − 6.1 ) 4.71 + 3.2 ) 4.71 + 1.5 ( − 1.39 ∗ 4.71 + 3.2 ) 4.71 + 1.5 ( − 6.55 + 3.2 ) 4.71 + 1.5 − 3.35 ∗ 4.71 + 1.5 − 15.8 + 1.5 − 14.3
Relative error: ∣ − 14.263899 + 14.3 ∣ ∣ − 14.263899 ∣ ≈ 0.25 % \frac{|-14.263899 + 14.3|}{|-14.263899|} \approx 0.25\% ∣ − 14.263899∣ ∣ − 14.263899 + 14.3∣ ≈ 0.25%
一个算法,如果初始数据的小变化 会导致最终结果的小变化 ,则称为 稳定(stable) ;否则称为 不稳定(unstable) 。如果只有在某些初始数据的选择下才稳定,则称为条件稳定(conditionally stable) 。
假设 E 0 > 0 E_0 > 0 E 0 > 0 初始误差(initial error) ,E n E_n E n n n n
如果 E n ≈ C n E 0 E_n \approx CnE_0 E n ≈ C n E 0 线性增长(linear growth) 。
线性增长的误差通常是无法避免的,当 C C C E 0 E_0 E 0
如果 E n ≈ C n E 0 E_n \approx C^nE_0 E n ≈ C n E 0 指数增长(exponential growth) 。
指数增长的误差应该避免,因为即使 E 0 E_0 E 0 C n C^n C n
收敛率(rate of convergence) :设 lim h → 0 F ( h ) = L \displaystyle{\lim_{h\to 0} F(h) = L} h → 0 lim F ( h ) = L lim h → 0 G ( h ) = 0 \displaystyle{\lim_{h\to 0} G(h) = 0} h → 0 lim G ( h ) = 0 K K K ∣ F ( h ) − L ∣ ≤ K ∣ G ( h ) ∣ \displaystyle{|F(h)-L| \leq K|G(h)|} ∣ F ( h ) − L ∣ ≤ K ∣ G ( h ) ∣ h h h F ( h ) = L + O ( G ( h ) ) F(h)=L+O(G(h)) F ( h ) = L + O ( G ( h )) G ( h ) = h p ( p > 0 ) G(h)=h^p\ (p>0) G ( h ) = h p ( p > 0 ) p p p
Homework 1.3.7: 求各函数的收敛速度
( − 1 ) sign ⋅ ( 1 + significand ) ⋅ 2 exponent-bias (-1)^\text{sign} \cdot (1+\text{significand}) \cdot 2^{\text{exponent-bias}} ( − 1 ) sign ⋅ ( 1 + significand ) ⋅ 2 exponent-bias
符号位 sign:一般来说正数就是 0 负数就是 1。
尾数 significand / fraction:去除符号位后应被移到 1. xxxxx 1.\text{xxxxx} 1. xxxxx
对于一些不使用 hidden 1 策略的表示方式则移到 0.1 xxxxx 0.1\text{xxxxx} 0.1 xxxxx
指数 exponent:用移码表示,单精度浮点数的 偏移(bias) 为 127 127 127 1023 1023 1023
− 0.75 -0.75 − 0.75
单精度浮点数
最小值:指数 = 00000001,小数 = 000...000;x = ± ( 1 + 0.0 ) × 2 1 − 127 = ± 1.0 × 2 − 126 ≈ ± 1.2 × 1 0 − 38 x = \pm (1+0.0) \times 2^{1-127} = \pm 1.0 \times 2^{-126} \approx \pm 1.2 \times 10^{-38} x = ± ( 1 + 0.0 ) × 2 1 − 127 = ± 1.0 × 2 − 126 ≈ ± 1.2 × 1 0 − 38
最大值:指数 = 11111110,小数 = 111...111;x = ± ( 1 + 0.111 … 111 ) × 2 254 − 127 ≈ ± 2.0 × 2 127 ≈ ± 3.4 × 1 0 38 x = \pm (1+0.111\ldots 111) \times 2^{254-127} \approx \pm 2.0 \times 2^{127} \approx \pm 3.4 \times 10^{38} x = ± ( 1 + 0.111 … 111 ) × 2 254 − 127 ≈ ± 2.0 × 2 127 ≈ ± 3.4 × 1 0 38
最小分度:2 − 23 2^{-23} 2 − 23 log 10 2 − 23 ≈ − 6.92 \log_{10}{2^{-23}}\approx -6.92 log 10 2 − 23 ≈ − 6.92
双精度浮点数:
最小值:指数 = 00000000001,小数 = 000...000;x = ± ( 1 + 0.0 ) × 2 1 − 1023 = ± 1.0 × 2 − 1022 ≈ ± 2.2 × 1 0 − 308 x = \pm (1+0.0) \times 2^{1-1023} = \pm 1.0 \times 2^{-1022} \approx \pm 2.2 \times 10^{-308} x = ± ( 1 + 0.0 ) × 2 1 − 1023 = ± 1.0 × 2 − 1022 ≈ ± 2.2 × 1 0 − 308
最大值:指数 = 11111111110,小数 = 111...111;x = ± ( 1 + 0.111 … 111 ) × 2 2046 − 1023 ≈ ± 2.0 × 2 1023 ≈ ± 1.8 × 1 0 308 x = \pm (1+0.111\ldots 111) \times 2^{2046-1023} \approx \pm 2.0 \times 2^{1023} \approx \pm 1.8 \times 10^{308} x = ± ( 1 + 0.111 … 111 ) × 2 2046 − 1023 ≈ ± 2.0 × 2 1023 ≈ ± 1.8 × 1 0 308
最小分度: 2 − 52 2^{-52} 2 − 52 log 10 2 − 52 ≈ − 15.65 \log_{10}{2^{-52}}\approx -15.65 log 10 2 − 52 ≈ − 15.65