本篇笔记介绍了计算机系统中的内存层次结构及其关键技术。首先讨论了 SRAM 和 DRAM 两种基本的内存技术,并引入内存层次的概念。随后详细阐述了 Cache 的工作原理,包括直接映射、全相连和组相连三种映射策略,以及处理 Cache 命中与缺失的各种策略。最后介绍了虚拟内存技术,重点讨论了页表的概念和 TLB 的应用,以及它们在地址转换过程中的作用。通过这些技术的结合,计算机系统得以在保证性能的同时有效管理内存资源。(由 claude-3.5-sonnet 生成摘要)
1. Memory Hierarchy
在前文中,我们将 instruction 和 data 存储在内存中,而内存的读写也有快慢之分,这里介绍两种常用的内存技术:
- 静态随机访问存储器(Static Random Access Memory, SRAM):
- 数据存储在晶体管中(通常用 6-8 个晶体管表示一个位),无需刷新。
- 读写速度快,但是空间(指占用的物理空间)占用高。
- 动态随机访问存储器(Dynamic Random Access Memory, DRAM):
- 数据存储在电容中,需要定期刷新。
- 读写速度慢(一般是 SRAM 的 5-10 倍),但是空间占用低。
显然,我们不可能把所有内存数据都用 SRAM 存储,只能将其中一小部分放在 SRAM 中(一般是缓存(cache)),而大部分放在 DRAM 中(一般是 主存(main memory)),这就是 内存层级(memory hierarchy) 的概念。

2. Cache
由于 CPU 的执行速度远快于主存(使用了 DRAM)的速度,如果直接从 DRAM 中读写数据,CPU 就必须为了等待主存而暂停若干个时钟周期,这就是 CPU 与主存速度不匹配产生的矛盾。为此我们需要引入 cache 技术。可以关注到程序对内存的访问有如下特点:
- 时间局部性(temporal locality),即近期访问的项目很有可能会在短时间内再次被访问。例如循环中的指令、induction variables (循环中用来计数的变量) 等。
- 空间局部性(spatial locality),即近期访问项目附近的项目也有可能会在短时间内再次被访问。例如连续的指令执行,或者数组变量等。
利用好这些性质,我们可以设计 cache 来在合理成本的代价下大幅优化对内存的读写速度。
2.1. Cache Mapping Strategies
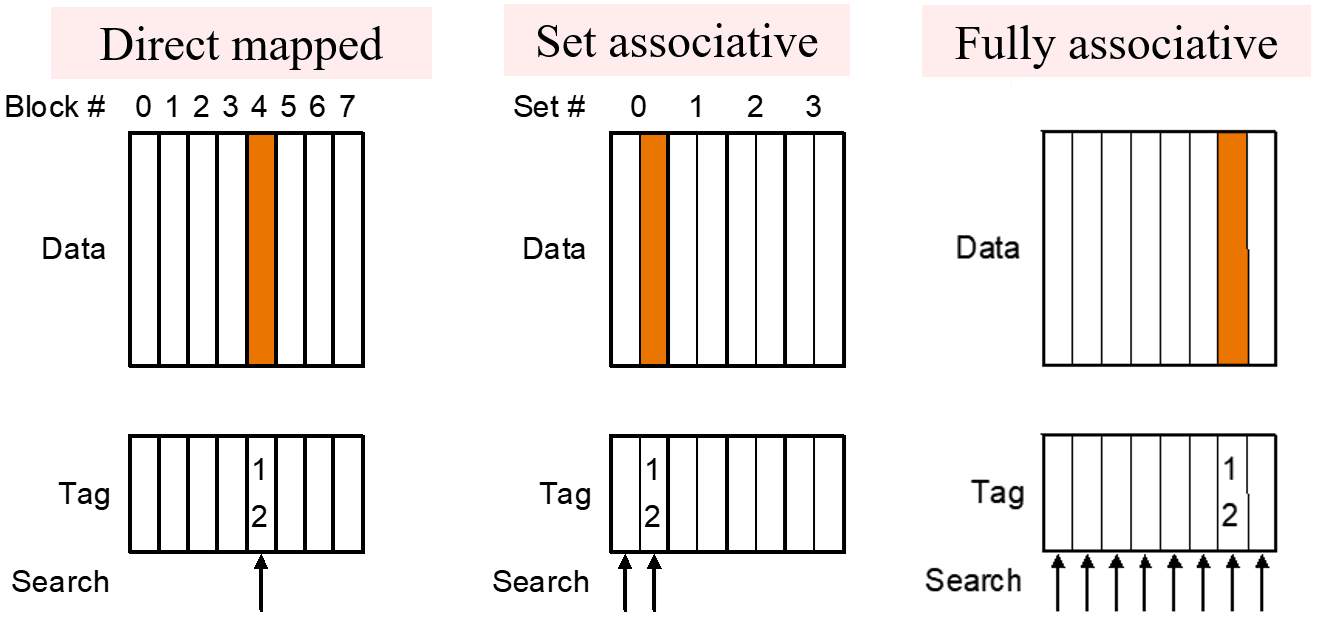
| 问题 | 直接映射 | 全相连 | 组相连 |
|---|---|---|---|
| Q1: Block Placement | 每个块只能映射到缓存中的一个位置:地址 MOD 缓存块数量 | 块可以放置在缓存中的任意位置 | 块可以放置在一个组中的任意位置,地址 MOD 组数量;-路组相连缓存中,每组有 个块 |
| Q2: Block Identification | 使用索引字段选择块(直接映射) | 使用标签字段匹配块地址 | 使用索引字段选择组,使用标签字段匹配组内块地址 |
| Q3: Block Replacement | 不存在替换问题,因为每个块只能映射到一个固定位置 | 替换策略包括随机替换、LRU(最近最少使用)、FIFO(先进先出) | 在组内进行替换,替换策略包括随机替换、LRU(最近最少使用)、FIFO(先进先出) |
2.1.1. Direct Map
将相邻的若干个 byte 合并为一个 块(block),下文关于 cache 的讨论都是以 block 作为基本单元进行的。我们将 byte address 的低若干位(称为 块内偏移(byte offset))拿掉,就可以得到对应的 block address。则一个 block 中包含 个 bytes。 Block
直接映射(direct map) 的策略是将每个内存中的 block 唯一映射到一个缓存的 block 中。
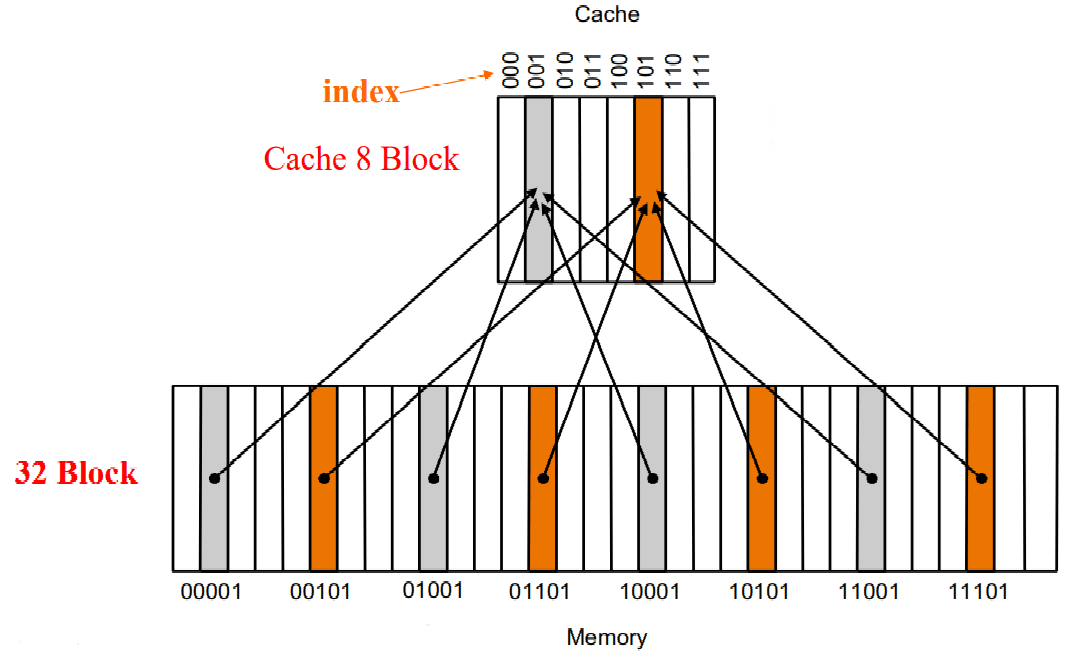
如上图所示:memory 有 个 block,cache 有 个 block,直接根据 memory 地址的低 3 位作为 cache 地址。我们将这个低 3 位称为 索引(index)。
为了知道 cache 中实际存放的到底是 memory 中的哪个 block,我们在 cache 中还需要存储 memory 地址的高几位(上图中就是高 2 位)。我们将这个高 2 位成为 标签(tag)。
另外,我们需要一个 有效位(valid bit) 来判断 cache 中存储的这个 block 是否是有效的。初始时全部无效,valid bit 为 0;当从内存中取出一个 block 后,就变成有效的了,valid bit 为 1。cache hit 当且仅当 valid bit 为 1 且 tag 与目标地址一致。

- tag:用于标识对应内存块的唯一性
- index:用于定位缓存中块的位置
- offset / byte offset:用于定位块内具体的数据
Tip: direct map cache 相关计算题
2.1.2. Fully Associative
全相连(fully associative) 策略简单来说就是 block 可能存放到 cache 中的每一个位置(因为它们都有连线),但坏处是我们在判断 hit 时的复杂度大大增加(需要一次跟所有 cache 中的 block 比较看是否 hit)。
- 注意,全相连的实现中没有 index,无论在地址划分还是在 cache 空间中。
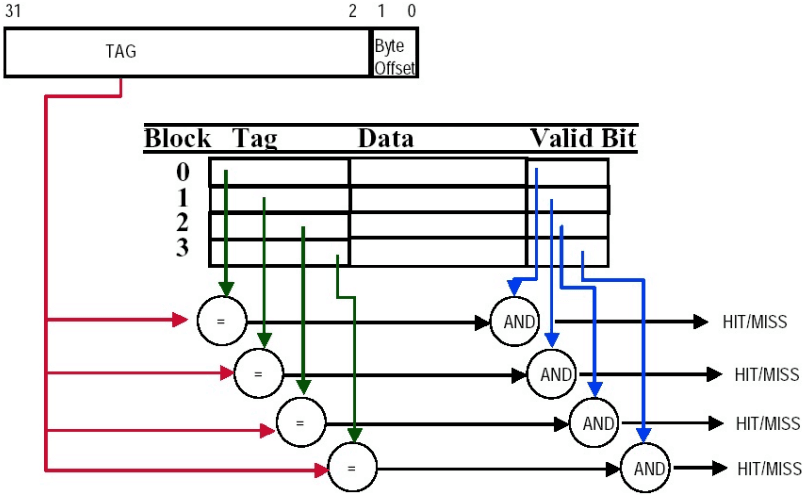
另外,在替换 cache block 时也有多种策略可以采用:
- 随机替换(random replacement):随机一个 cache 中的 block 进行替换(需要实现一个随机数生成算法)。
- 先进先出(first in first out, FIFO):即选择进入时间最少的 block 覆盖掉。
- 最近最少使用(least recently used, LRU):选择上一次使用时间距离现在最远的 block 覆盖掉(需要一些额外的位记录信息)。
2.1.3. Set Associative
组相连(set associative) 策略是一种介于直接映射策略和全相连策略的策略。即每个 block 根据其 block address 可以对应到一组 cache blocks 中。其中每一组中都采用全相连中介绍过的替换算法。
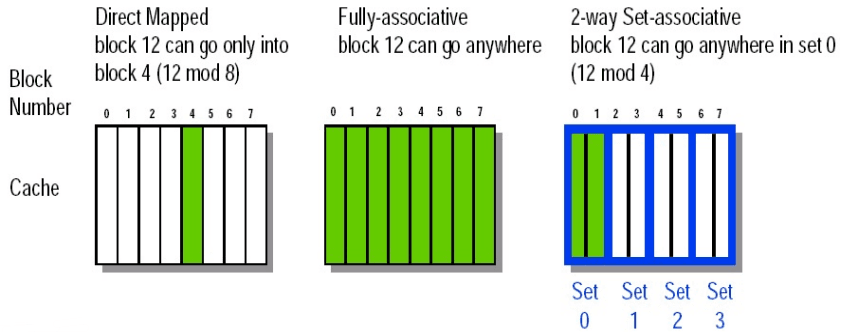
像上图就是一个 2-way set associative 的示意图,展示了数据在 set-associative 的 cache 中的去向。更严谨的,我们可以画出其原理图,以 4-way set associative 的 cache 为例(见下图),我们用一行表示一个组,并使用 MUX 在组中选择匹配的 line。
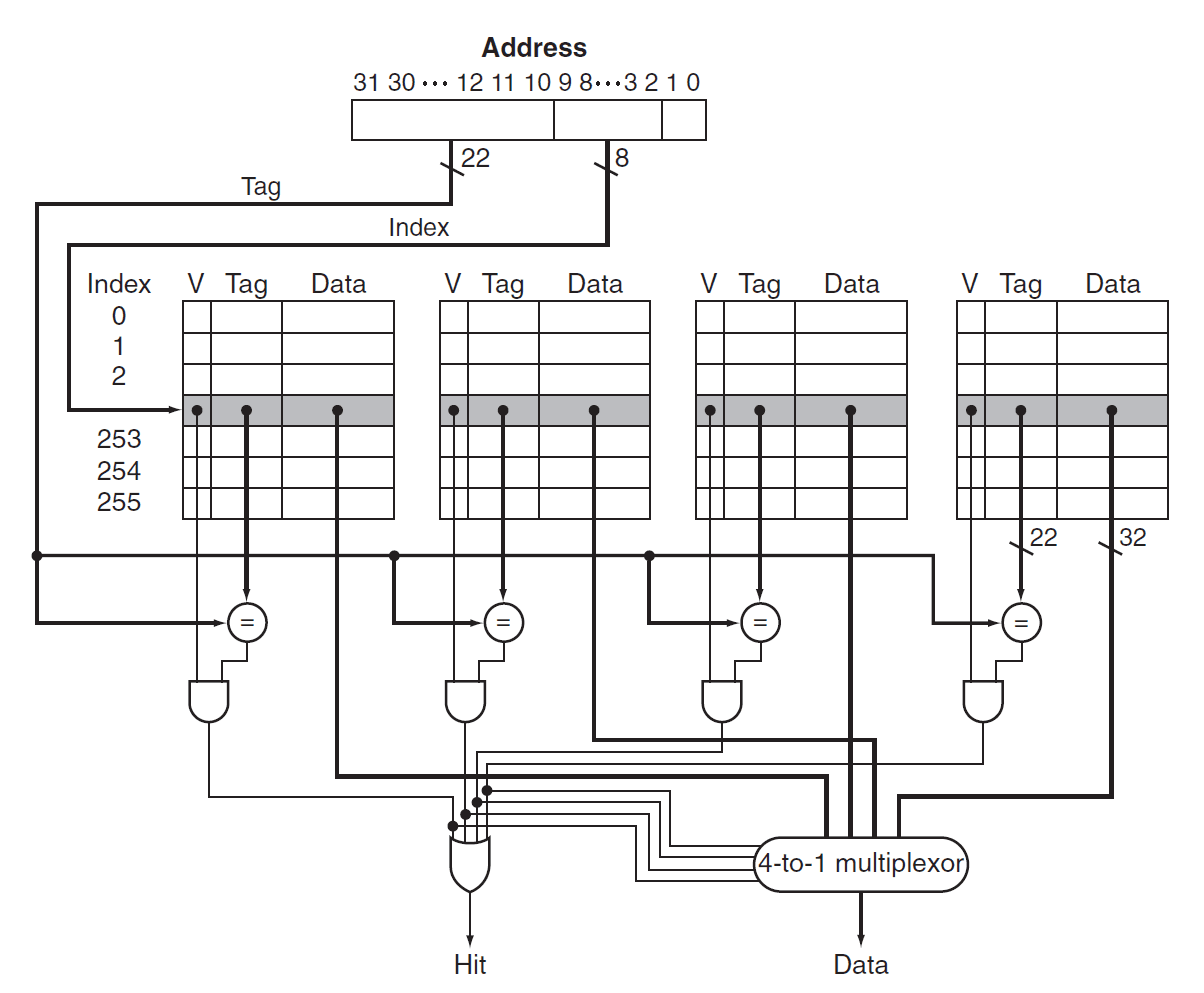
特别地,我们称组的大小为 associativity,则判断 hit 时需要比较的次数就等于 associativity。
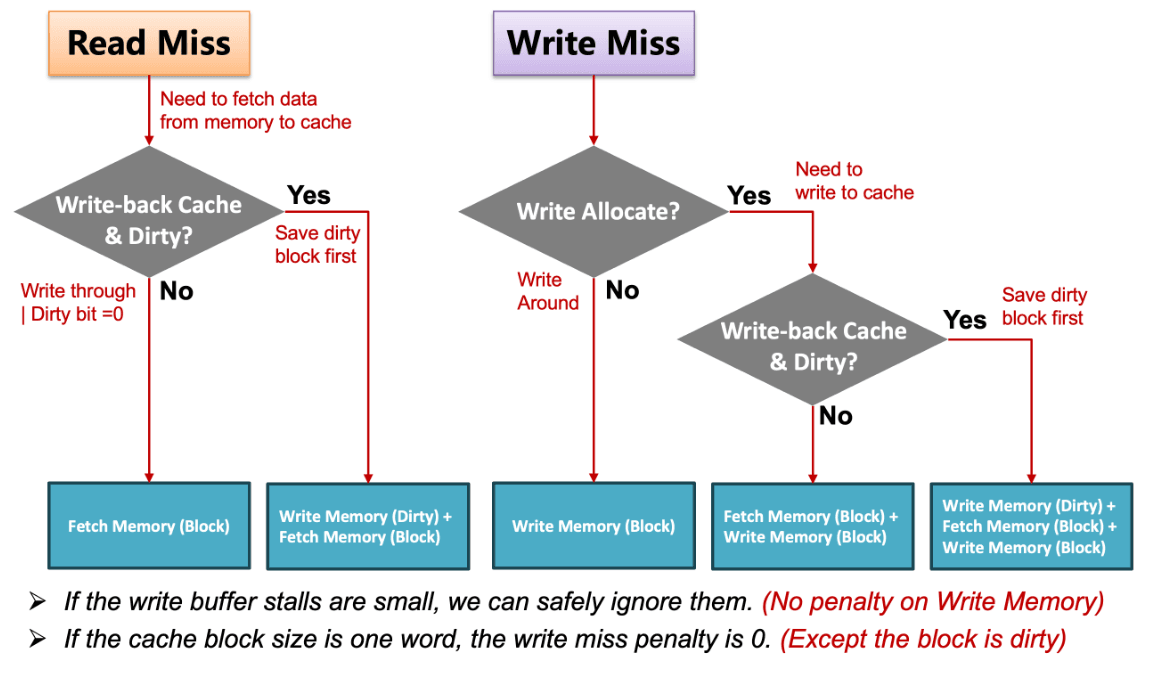
2.2. Handling Hits & Misses
我们根据 read / write、hit / miss、inst / data 的情况进行分类讨论,这一部分的理解会在后文关系到性能计算。
- Read
- Hit:直接就从 cache 里读就好了
- Miss
- Data:从 memory 里把对应 block 拿到 cache,再读取相应内容。
- Inst:暂停 CPU 运行,从 memory 里把对应的 block 拿到 cache,从第一个 step 开始重新运行当前这条指令。
- Write
- Hit
- 写穿(write-through) 策略:每次写数据时既写在 cache 中,也写到 main memory 中。好处是 cache 和 main memory 始终是一致的。
- 一个常见的改进是引入 write buffer——即需要写入 main memory 时先加入到缓冲队列中,并允许 CPU 继续运行了。当 write buffer 满了的时候,也需要暂停处理器来做写入 main memory 的工作,直到 buffer 中有空闲的 entry。(因此,如果 main memory 的写入速率低于 CPU 产生写操作的速率,多大的缓冲都无济于事。)
- 写回(write-back) 策略:只将要修改的内容写在 cache 里,当这个 block 要被替换掉的时候才将对应的修改写回 main memory。这种情况需要在 cache 中额外创建一个 脏位(dirty bit) 用于记录该 block 是否发生或修改。这对于在同一个 block 中连续有多次修改情况优化是巨大的。
- 写穿(write-through) 策略:每次写数据时既写在 cache 中,也写到 main memory 中。好处是 cache 和 main memory 始终是一致的。
- Miss
- write-around 策略:直接在 main memory 中进行修改,不用拿到 cache 里了。一般搭配 write-through 策略。
- write-allocate 策略:先将对应 block 拿到 cache 中再写入。对于 write-back 策略,必须搭配这一策略。
- Hit
2.3. Cache Performance
注意到无论我们采用什么策略,都不能保证 cache 的每次访问都 hit。而一旦 miss,就需要等待若干时钟周期去访问主存,这一代价成为 miss penalty。在计算 cache 性能时,必须要考虑这一部分。
平均内存访问时间(average memory access time) 定义为:
一般用 CPU 时间来衡量 cache 性能,即在 CPU 执行时间的基础上加上因为 cache miss 而惩罚的时间:
- 读延迟周期:
- 写延迟周期:
- 如果 write buffer penalty 很小,可以忽略不计。
- 如果 block size 为 ,则 write miss penalty 近乎于 。
- 在 write-through 的 cache 中,read penalty 和 write penalty 可近似为相同的,由此得到:。
3. Virtual Memory
为了让多个程序可以共用一个地址,同时提高内存寻址空间,我们可以引入 虚拟内存(virtual memory) 的概念,这是相对于 物理内存(physical memory) 的而言的。当然,(需要用到的)数据还是需要被加载到物理内存中,本小节主要关注的是 虚拟地址(virtual address) 和 物理地址(physical address) 进行转换的技术。
3.1. Page Table
页(page) 是虚拟内存和物理内存的基本单元,可以类比 cache 中 block / line 的概念。一方面,我们利用了内存访问的连续性;另一方面,我们可以减少对页表大小的要求,因为虚拟地址和物理地址的 page offset 部分是相同的,不需要转换。
通过虚拟内存技术,我们可以让程序访问超过物理内存本身限制的内存,这是通过和磁盘 的交互得到的,这其实比较类似于操作系统中 swap 内存的概念(但其实是两个东西)。也就是说,程序所需要的内存数据一开始在磁盘中,并通过虚拟地址的方式索引。等到程序用到时才从磁盘中取出加载到物理内存里,由于这一物理内存地址是实时分配的,我们需要通过一个 页表(page table) 记录虚拟内存到底被对应到了物理内存的哪一地址,根据这一物理地址我们才能在主存中查找数据。
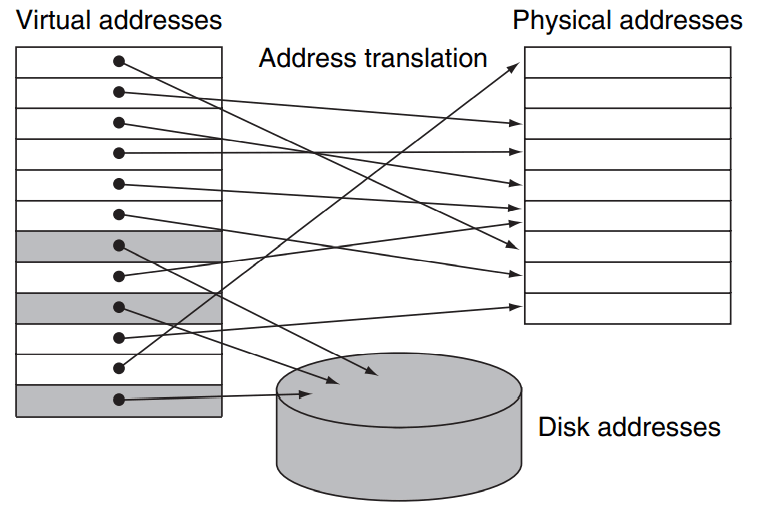
当我们在 page table 中 miss 时,实际上就是发生了 页错误(page fault),即我们请求的页并不在主存中,而在 disk 中。当 page fault 发生时,一般由操作系统负责将对应页从磁盘中取出,并载入到主存中。这也是为什么使用虚拟内存技术时,一般只能使用 write back 策略而不能使用 write through 策略,因为对 disk 的写是极慢的,不能接受一旦 miss 就只能等待 disk 写。
有人把 cache 理解成 SRAM 层和主存(DRAM 层)的缓存,而把 page table 理解成 DRAM 层和 disk 的缓存。这种说法大体上是说得通的,但并不是很严谨。就比如,在 page table 中我们并不实际存储数据,而是只存放虚拟地址和物理地址的转换关系,数据仍是存储在物理内存(主存;DRAM 层)中。 Page table 是 DRAM 到 disk 的缓存?
因为 page table 中的每一个位置都可以存放任意一个物理地址(即每个虚拟地址都可能对应任一个物理地址),而课件把 page table 看成一种 DRAM 层到外部存储的 cache,从而说 page table 是 fully-associative 的。但这种全相连的实现方法是通过地址转换+根据物理地址寻址实现的,而不是 cache 的那种直接连线,两者还是有不小的区别的。不过共同点是我们都可以实现 LRU 策略等等(取决于在 page faults 发生时怎么操作)。 而如果换一个理解,把 page table 看作是虚拟地址到物理地址的转换函数(假装是另一种定义地不太严谨的 cache?),那又可以说 page table 是 direct mapped 的。因为我们其实是直接根据虚拟地址在 page table 中查表,这和 direct mapped cache 的实现类似。 因此我觉得这个怎么说取决于具体语境,取决于你怎么理解。个人认为不必太纠结这个。 Page table 是 fully-associative 还是 direct mapped?
3.2. Translation-lookahead Buffer
注意到 page table 很大,需要存储在 DRAM 中。即和主存一样,对 page table 的访问其实是较慢的,那有没有什么办法给 page table 再实现一个缓存呢?这就是 快表(Translation-lookahead Buffer, TLB) 扮演的工作。TLB 放在 SRAM 中,一般采用组相连的策略(也可以是其他两种),作为 page table 的 cache。当 TLB 命中时,能直接返回 physical address,否则才需要在 page table 中重新查找。
如果把 TLB 和 page table 结合起来,并且考虑根据物理地址从 cache 和主存中找数据的步骤,就可以得到下面这张流程图,据此也很好分析课件中给出的 possible / impossible 判断。
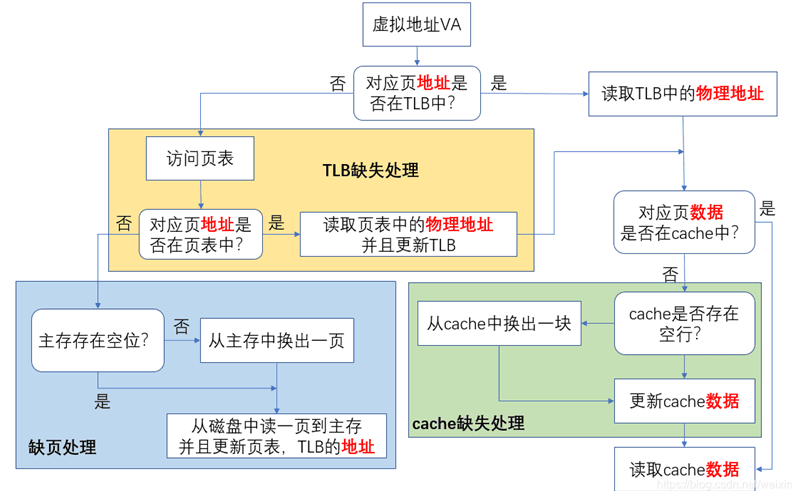
- 如果 page table 中 miss,则不可能在 TLB 中 hit。因为 TLB 中的数据是从 page table 中取出并放入的。
- 如果在 page table 和 tlb 中 miss,则不可能在 cache 中 hit,因为页如果在 cache 中说明其有被分配物理地址,这种情况下一定能在 page table 中查到。

一般在组相连的 TLB 中使用 LRU 策略,但完整的 LRU 策略实现开销较大,一般采用一种近似的 LRU 策略。即在 TLB 中加入一个 rel bit。CPU 每隔一段时间将 rel bit 置 0,如果进行了访问就将 rel bit 置 1。当需要从 TLB 中移出 line 时,选择一个 rel bit 为 0 的行即可。
如果要实现写操作,我们在 TLB 中也需要实现 dirty bit。这是因为根据 write-back 策略,我们如果对一个页进行了修改,就必须把其 dirty bit 设置为 1。而根据 write-back 策略,这个页肯定已经被加载到 TLB 中,所以我们只需要在 TLB 中讲其 dirty bit 设置为 1,并且在这个页被移出 TLB 时把修改应用到 page table 中即可。 设想如果我们没有在 TLB 中实现 dirty bit,则每次标记 dirty bit 都需要对 page table 进行操作,这显然会带来额外的时间开销;而如果不操作的话,数据一致性就不能保证。 TLB 需要 dirty bit 吗?