1. Introduction to Computer
1.1. Computer Organization
- 计算机系统(computer system)
- 软件(software)
- 硬件(hardware)
- CPU
- 控制单元(control unit)
- 数据通路(datapath)
- Path: multiplexor
- ALU: adder, multiplier
- Registers
- ......
- 内存(memory)
- I/O 接口(interface)
- Input: keyboard, mouse
- Bidirectional: RS-232、USB
- Output: VGA、LCD
- CPU
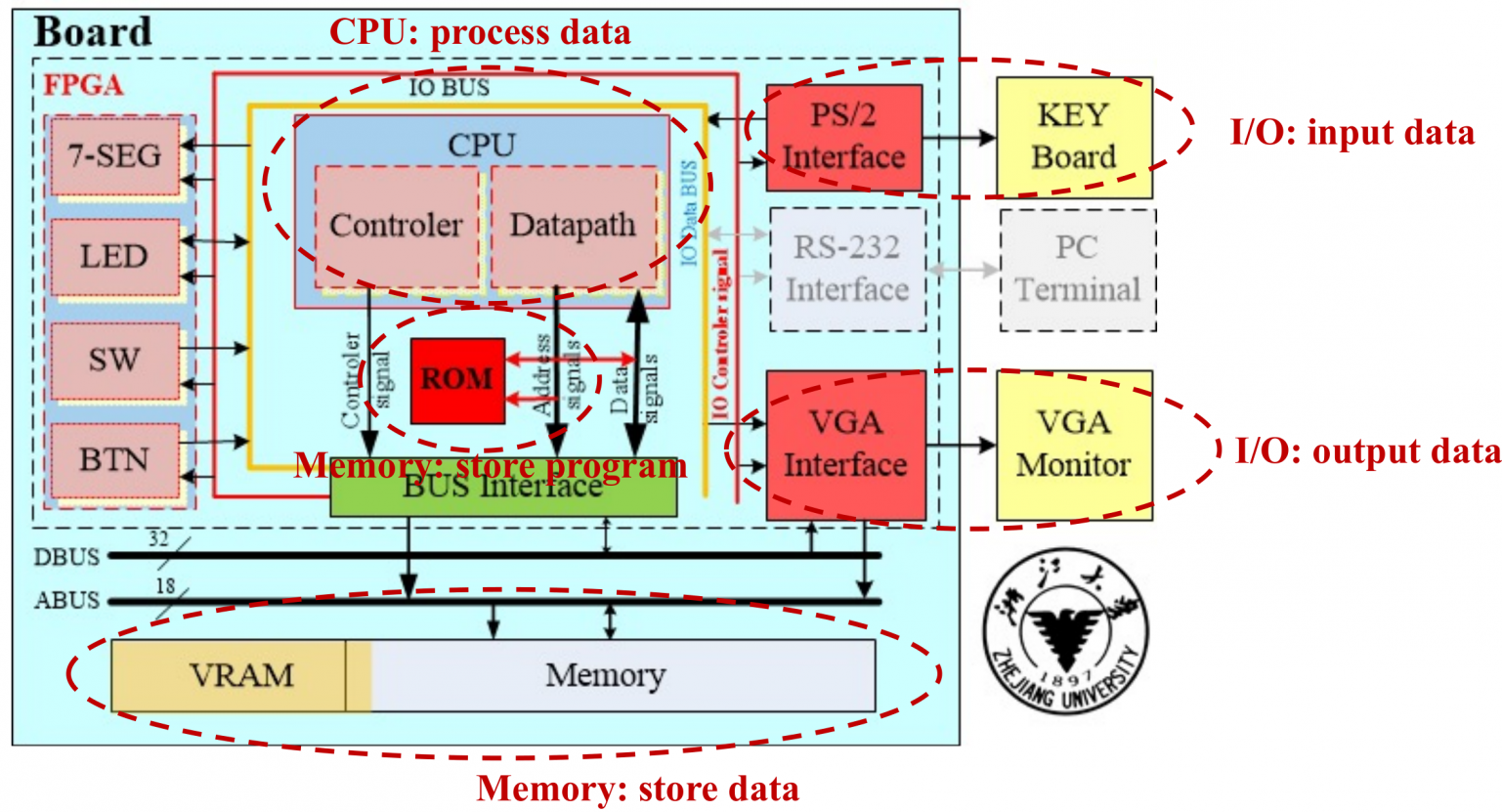
这个就是本课程实验部分大致的原理图。
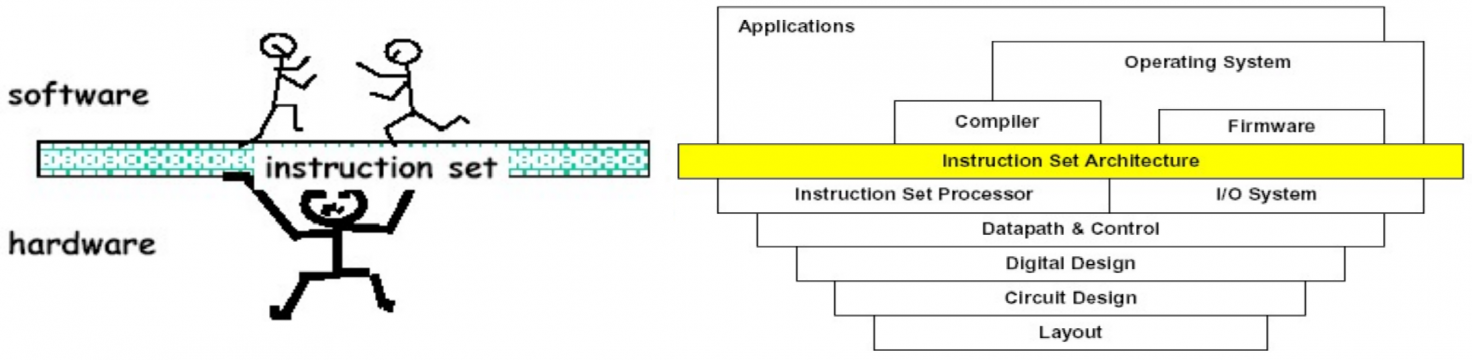
1.1.1. Instruction Set
指令集(instruction set) 是连通软件和硬件之间的桥梁,我们将在 Chapter 2 中重点介绍这一部分。
2. Performance Measurement
- 响应时间(response time) / 执行时间(execution time):完成一个任务所花费的时间。
- 吞吐率(throughput) / 带宽(bandwidth):单位时间内完成的任务数量。
在本章节或者后面的章节中,我们可能会关注处理器的性能或改进前后的 性能提升(speedup)。
-
性能(performance):执行时间的倒数。。
-
相对性能(relative performance): 比 快了几倍( is times faster than ).
-
持续时间(elapsed time):从任务开始到任务结束所花费的时间。
-
CPU 时间(CPU time):该任务占用 CPU 的时间。
- 用户 CPU 时间(user CPU time):用户态的程序在 CPU 上运行的时间。
- 系统 CPU 时间(system CPU time):内核态的程序在 CPU 上运行的时间。
当我们衡量一条指令的 CPU 时间时:
-
时钟周期(clock period / clock cycle time):一个 时钟循环(clock cycle) 的持续时间。
- e.g.
-
时钟频率(clock rate / clock frequency):一秒内的时钟周期数。。
- e.g.
-
时钟周期数(clock cycles):程序所需要的周期数。
-
指令数(instruction count, IC):任务执行了多少条指令。
-
周期数(clock cycles per instruction, CPI):每条指令所需要的周期数量。一般 CPI 直接指 平均周期数(average clock cycles per instruction, Avg. CPI),即所有指令的周期数的平均值。CPI 是由硬件实现决定的,在第四章会进一步讲到。
对于一个指令数为 的程序,其:
2.1. Three Walls
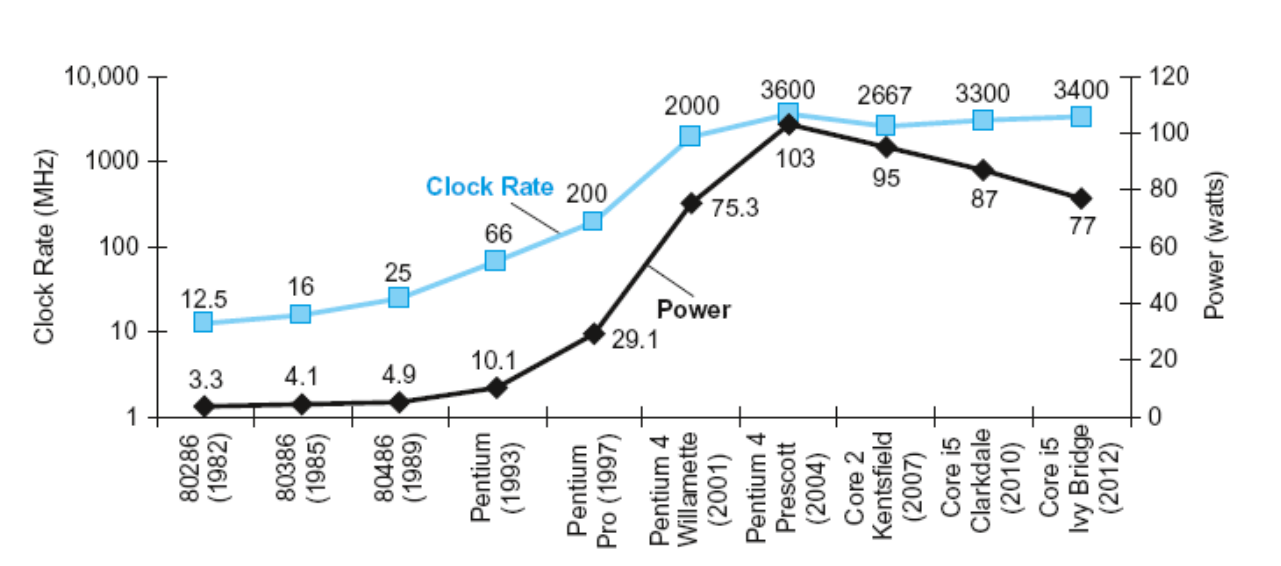
- Power Wall:主频提高了很多,但功耗并没有得到这么多的提升,因为我们降低了工作电压 (5V-1V)。现在工作电压不能再降低了(否则泄漏电流占比太大),因此我们不能再提高功率了。以 CMOS IC technology 为例,其能耗(power) 公式为:(电容负载(capacitive load))
-
Memory Wall:Memory 的性能增长不如 CPU 的性能增长,大部分时间花在读写内存了。
-
ITP Wall:难以在单个进程的指令流中找到足够的并行性,以使性能更高的处理器核心保持忙碌。
2.2. MIPS
百万指令数每秒(Millions of Instructions Per Second, MIPS):
但注意,只有在其他参数一致时 MIPS 才有比较意义,不同的 ISA 之间不能仅凭 MIPS 比较。
2.3. Pitfall: Amdahl's Law
阿姆达尔定律(Amdahl's Law) 用于计算系统某一部分性能提升后对整体性能的影响。它指出,系统整体性能的提升受限于系统中未被改进部分的性能。
-
推论:make the common case fast
-
注意:不是说 MIPS 越高性能就越好,因为 MIPS 没有考虑指令的复杂程度等等(如精简指令集 vs 复杂指令集)。MIPS 往往是用来描述同一个处理器或者同一个指令集对于任务的优化。
3. Eight Great Ideas
计算机组成与设计中的八大重要思想。
3.1. Design for Moore's Law
设计紧跟摩尔定律。
Integrated circuit resources double every 18-24 months. 单芯片上所集成的晶体管资源每 18 至 24 个月翻一番。 摩尔定律(Moore's Law)
- Design for where it will be when finishes rather than design for where it starts.
3.2. Use Abstraction to Simplify Design
通过抽象化来简化设计,使设计更易于理解和管理。
- 采用层次化、模块化的设计。
3.3. Make the Common Case Fast
加速大概率事件。
- 如部分指令集设计中的 0 号寄存器。
3.4. Performance via Parallelism
通过并行提升性能。
3.5. Performance via Pipelining
通过流水线提升性能。
- 换句话说就是,每个流程同时进行,只不过每一个流程工作的对象是时间上相邻的若干产品;
- 相比于等一个产品完全生产完再开始下一个产品的生产,会快很多;
- 希望每一个流程的时间是相对均匀的;
3.6. Performance via Prediction
通过预测提高性能。
- 例如先当作
if()条件成立,执行完内部内容,如果后来发现确实成立,那么直接 apply,否则就再重新正常做。 - 这么做就好在(又或者说只有这种情况适合预测),预测成功了就加速了,预测失败了纠正的成本也不高。
3.7. Hierarchy of Memories
不同类型的存储器具有不同的速度和容量,不同层次使用不同类型的存储器以提高性能并节约成本。
- Disk / Tape -> Main Memory(DRAM) -> L2-Cache(SRAM) -> L1-Cache(On-Chip) -> Registers
3.8. Dependability via Redundancy
通过冗余设计来提高系统的可靠性,确保单点故障不会导致系统崩溃。
- 类似于卡车的多个轮胎,一个模块 down 了以后不会剧烈影响整个系统;