1. Introduction to Instruction-Level Parallelism
1.1. Terminologies
-
时延(latency):单个指令从进入流水线开始,到它完成执行并可以写会结果所需要的时钟周期数.
-
功能单元时间(function unit time):指指令在 EX/MEM 阶段的 latency.
-
.
-
-
启动间隔(initiation interval):一个功能单元需要经过多少个时钟周期才能被重新使用.
-
对于 完全流水线的(full pipelined) 功能单元:.
-
对于 非流水线的(non-pipelined) 功能单元:.
-
这里 浮点数流水线中功能单元的时延与启动间隔

FP add 是四级流水线(),并且是完全流水线的(说明启动间隔为 )功能模块.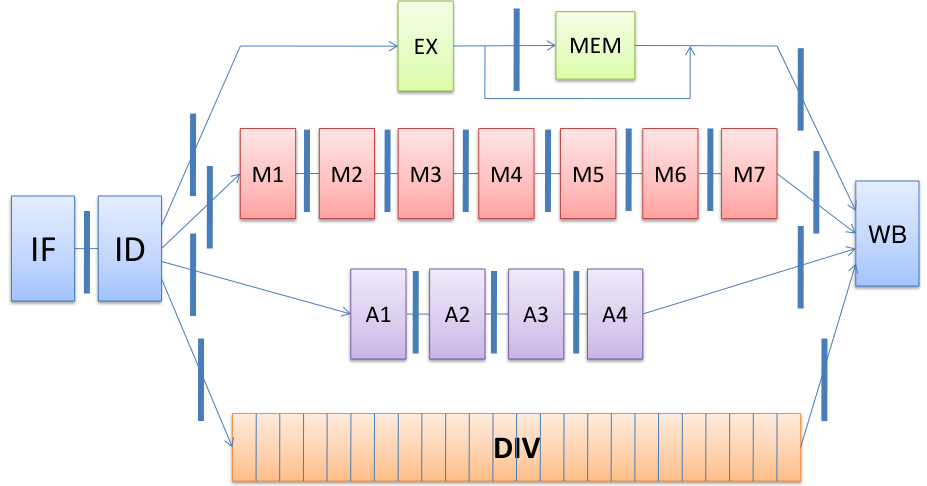
- 基本块(basic block):一段连续的、直线执行的代码.只有一个入口和一个出口,没有分支.
2. Dependencies & Hazards | 依赖与冒险
2.1. Structural Hazards | 结构冒险
2.1.1. Structural Hazards for the FP Register Write Port | 浮点数寄存器写端口结构冒险
-
浮点数流水线(顺序发射、顺序执行、乱序完成(out-of-order complete))导致的结构冒险问题:
-
(1) 单个时钟周期内多个 WB 操作.
-
(2) 写回顺序被打乱导致冒险.
-
-
解决方法一:增加写端口的数量,从而允许一个时钟周期内执行多个 WB 操作.、
-
解决方法二:通过移位寄存器,在指令译码阶段跟踪写端口的使用——因为在静态调度流水线中,必定是顺序执行的,且在译码阶段已经可以计算需要 stall 几个周期,因此也可以直接结算处在什么时候写回.

- 解决方法三:在指令试图进入 MEM 或 WB 阶段时进行 stall,在托马斯路等算法中可能再次用到.
2.2. Data Hazards | 数据冒险
2.2.1. RAW Dependences
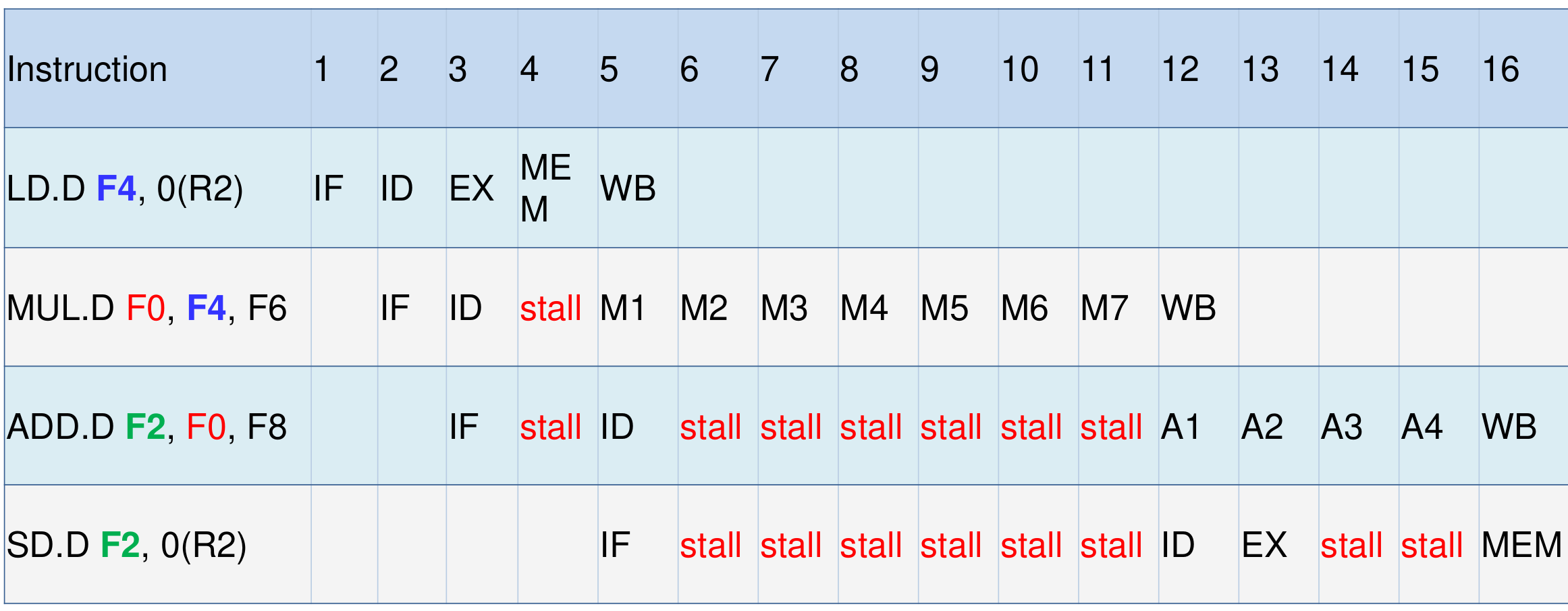
-
读后写依赖(read-after-write dependency, RAW dependency),又称 真数据依赖(true data dependency).
-
一般来说,只能通过 forwarding 或 stall 来解决.
通过 stall 解决 RAW 冒险
2.2.2. WAW Dependences
-
写后写依赖(write-after-write dependency, WAW dependency),又称 输出依赖(output dependency),是 命名依赖(name dependency) 的一种.
-
WAW 和 WAR 这两种命名依赖都可以通过重命名寄存器的方式解决.
通过 stall 解决 WAW 冒险
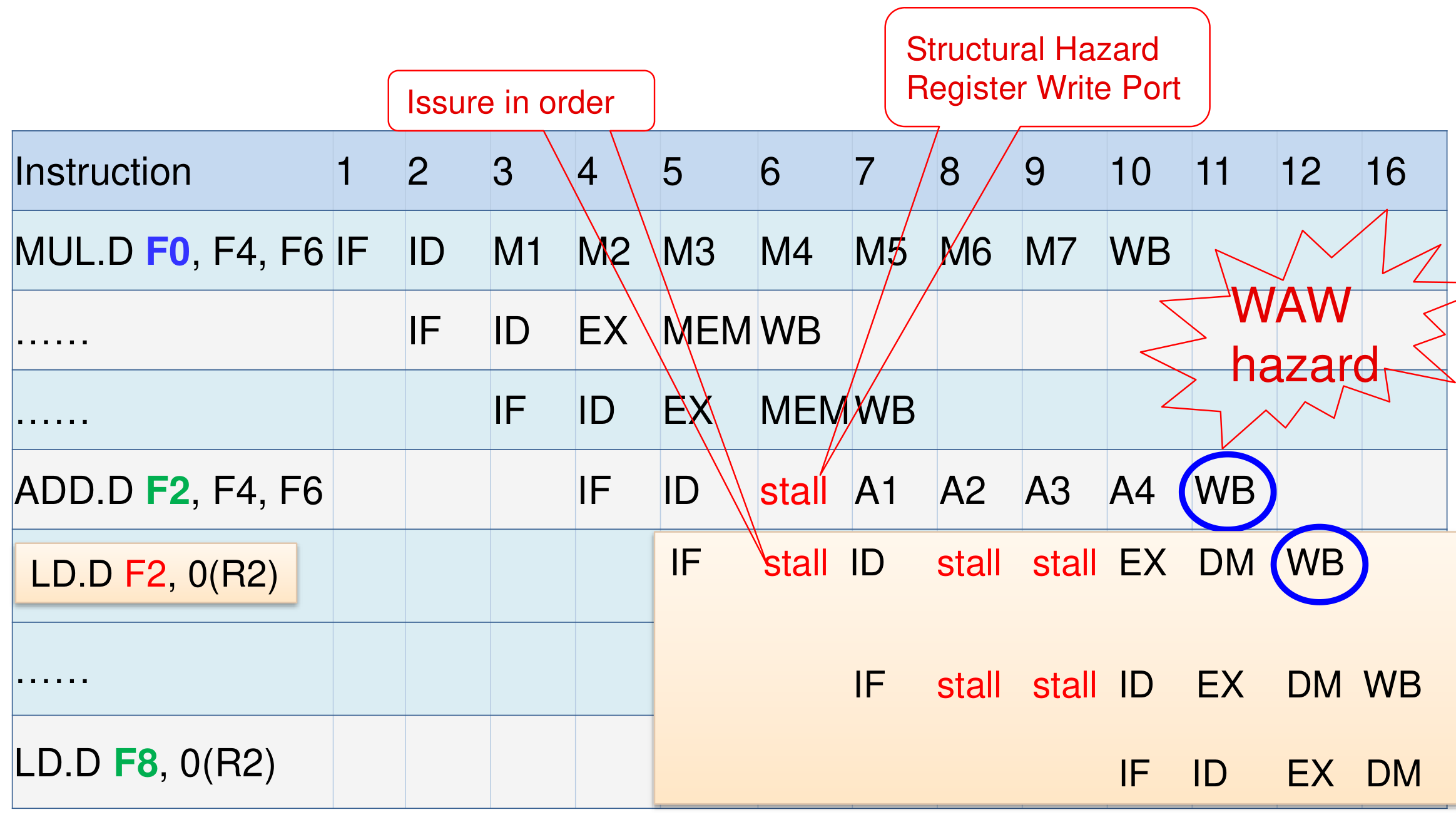
-
解决方法一:取消掉前一条指令的 WB 阶段,可以在 ID 阶段进行检测.
-
解决方法二:检测到冲突时阻滞在 ID 阶段(即后文小结的方法).
2.2.3. WAR Dependences
- 写后读依赖(write-after-read dependency, WAR dependency) 又称 反依赖(anti-dependency),是 命名依赖(name dependency) 的一种.
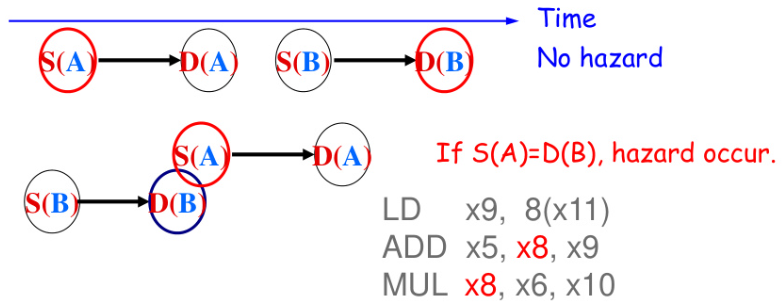
- 在大部分顺序发射、顺序执行的流水线(称为 顺序流水线(sequential pipeline))中,因为是顺序读取(一般都是尽可能早的读取出值),不会出现 WAR 冒险.
一种简单且常用的方法是,对于结构冒险、RAW 冒险和 WAR 冒险,全都在 ID 阶段进行判断,如果不行就在 ID 阶段暂停,等到依赖解除后再进行发射. 小结:顺序流水线解决结构冒险与数据冒险的方法

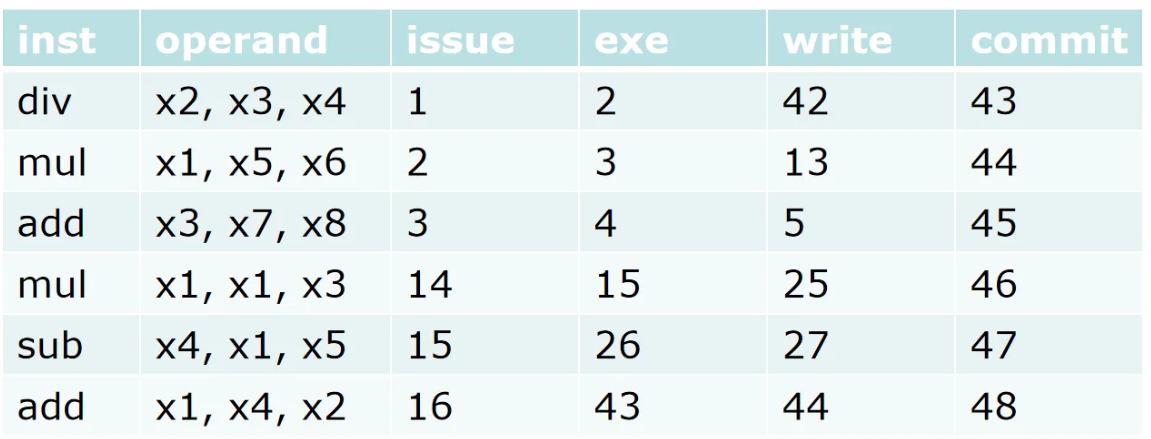
MIPS R4000 流水线
| IF | IS | RF | EX | DF | DS | TC | WB |
miss?
这里讲的冒险问题其实没听懂
2.3. Controls Hazards | 控制冒险
- 最常用的方法就是 stall(延迟分支(delayed branch)).
2.4. Hazards among FP Instructions
mark
3. Basic Compiler Techniques | 基本编译技术
在本节中,我们考虑以下 C 代码:
for (i = 999; i >= 0; i--) // typeof i is long long
x[i] += s; // typeof x[i] is double编译到 RISC-V 的结果如下:
Loop:
fld f0, 0(x1)
fadd.d f4, f0, f2
fsd f4, 0(x1)
addi x1, x1, -8
bne x1, x2, Loop3.1. Scheduling | 调度
- 使用 调度(scheduling) 优化本节实例代码,可以减少一个时钟周期的停顿.
调度前 |
调度后 |
|---|---|
|
|


3.2. Loop Unrolling | 循环展开
- 使用 循环展开(loop unrolling) 并进行调度,可以进一步减少每次迭代的平均周期数.
循环展开四次的结果 |
循环展开四次并调度的结果 |
|---|---|
平均每循环 6.5 个时钟周期
|
平均每循环 3.5 个时钟周期
|


- 这里假设了迭代次数是 的倍数,如果不是的话需要再后面再补上单迭代的循环,以确保总迭代次数不变.
TBD: 具体方法论
4. Dynamic Scheduling | 动态调度
-
回顾(计组知识):静态调度(static scheduling) 静态调度的流水线处理器在获取指令后会发射该指令,除非发现该指令存在数据依赖且无法通过 前递(forwarding) 来隐藏该指令,此时冒险检测硬件会暂停流水线,直到依赖清除后在获取新的指令.
-
动态调度(dynamic scheduling):通过硬件重排指令的执行阶段(允许 顺序发射(in-order issue) 但是 乱序执行(out-of-order execution))以减少停顿,并且不改变 数据流(data flow) 和 异常(exception behavior).
-
优点:
-
可以让在某个流水线上被编译的代码在其他流水线上也能高效运行.
-
能够处理在编译时无法处理的依赖,比如内存引用或数据依赖分支,或者采用现代的动态链接或分派.
-
能让处理器容忍无法预测的时延,比如对于高速缓存失效,可通过在等待失效解决时执行其他代码来实现这一点.
-
-
4.1. The Scoreboard Algorithm | 记分牌算法
-
带记分牌的流水线阶段:
IF - IS - RO - EX - WB.-
与 RISC-V 五级流水线的区别:
-
ID 阶段:分成了 发射(issue) 和 取数(read operands) 两个阶段.
-
MEM 阶段:省略,合并到 EX 阶段.
-
-
-
记分牌流水线工作流程:
-
IS
-
当且仅当 (1) 功能单元可用 (2) 没有其他活跃指令占用了相同的目标寄存器 时,发射指令.
-
可以避免结构冒险与 WAW 冒险.
-
-
RO
-
直到两个源操作数都可用时,才进行读取.
-
可以动态地避免 RAW 冒险.
-
-
-
记分牌的数据结构:
-
指令状态:
-
功能单元状态(function unit state):
-
:表明这个功能单元是否在执行某条指令.
-
:正在这个功能单元执行的指令操作.
-
:目标寄存器.
-
:源寄存器.
-
:源寄存器会由哪个功能单元产生(如有).
-
:源寄存器是否就绪(都就绪时才读),读完在下一周期要标记为 NO.
-
-
计算器结果状态:
-
记分牌状态 |
说明 |
|---|---|
|
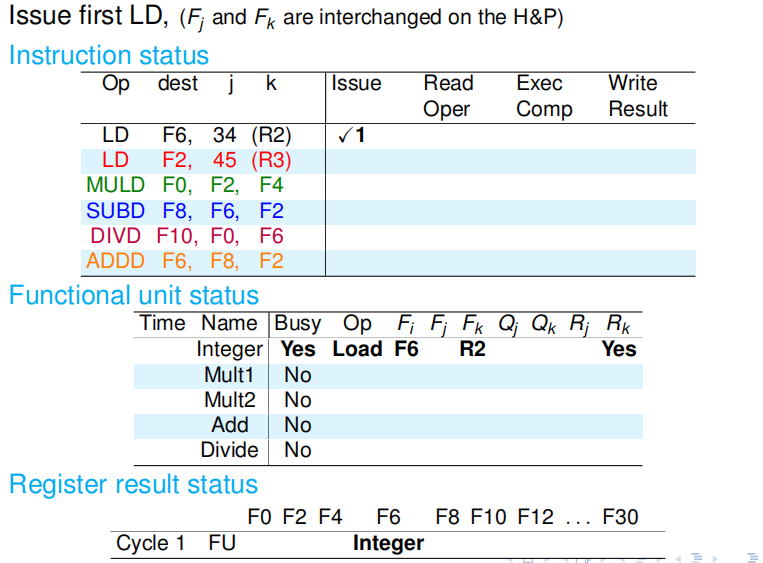
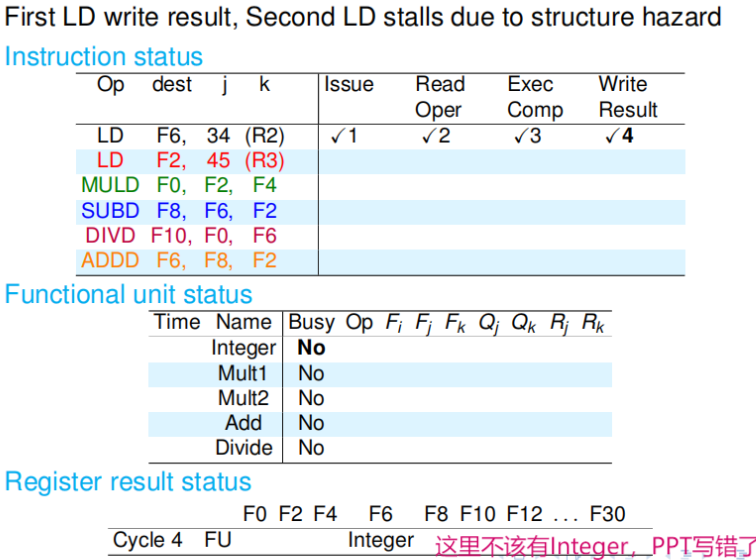
第一个周期:记分牌是空的,功能部件也都是空闲的,因此第一条指令顺利渡过发射阶段,并在周期结束的时候更新了记分牌. 注意看更新内容.整数部件现在显示忙碌,而 LD 指令的操作数不存在冒险,Rk 显示 Yes,在寄存器状态里标记 F6 即将被整数部件改写. |
|
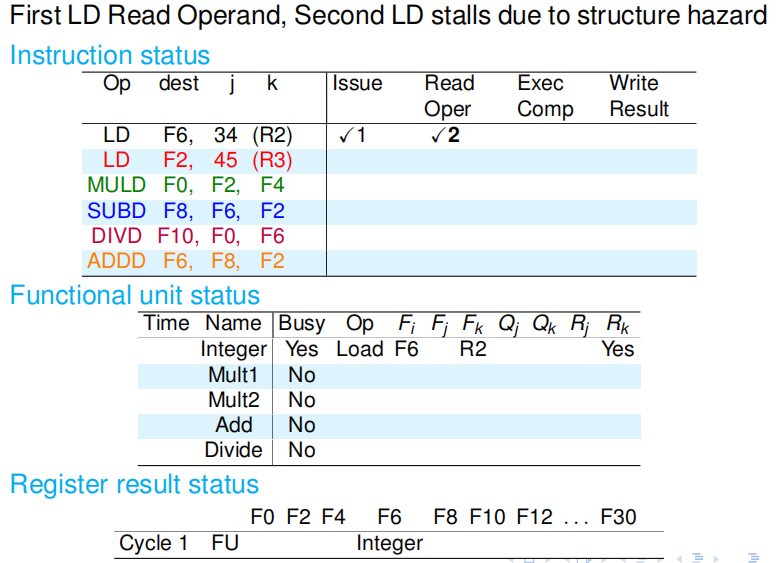
第二个周期:因为整数部件被占用了,所以第二条 LD 指令不能发射.同时第一条 LD 已经顺利渡过读数阶段,需要将 Rk 标记为 NO. 第二条 LD 在周期结束时不会更新记分牌. |
|
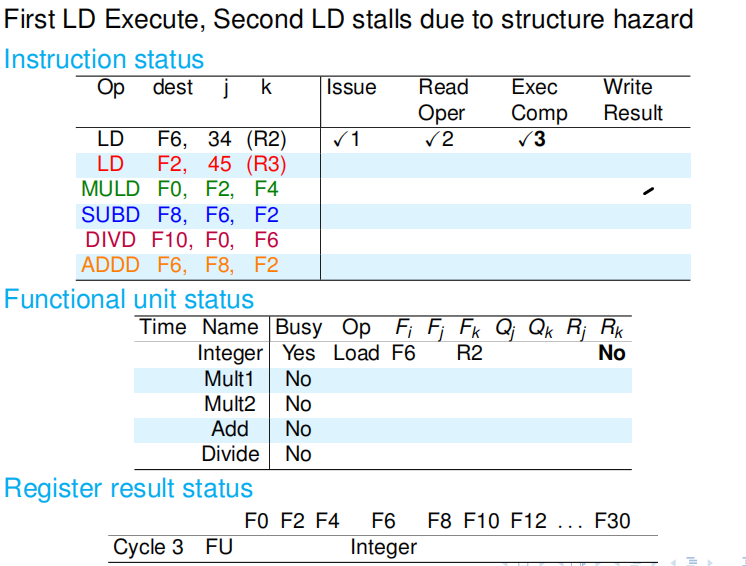
第三个周期:在流程解读一节,我们已经看到 INST 寄存器只有一个,所以发射阶段是阻塞的、顺序的.因为第二条 LD 没法发射,后面的指令都没办法发射. 第一条 LD 顺利渡过执行阶段,并在周期结束时改写了记分牌,这里主要是解放了 Rk(从 Yes 变为 No ),即表示自己不再要读取寄存器 R2. |
|
第四个周期:后续指令依旧没办法发射. 第一条 LD 顺利渡过写回阶段,阶段结束时清空功能状态,并且解放了寄存器状态(清除 F6 下面的 Integer ),即 F6 已经被写完了,F6 不再是“即将被整数部件写”的状态. |
|
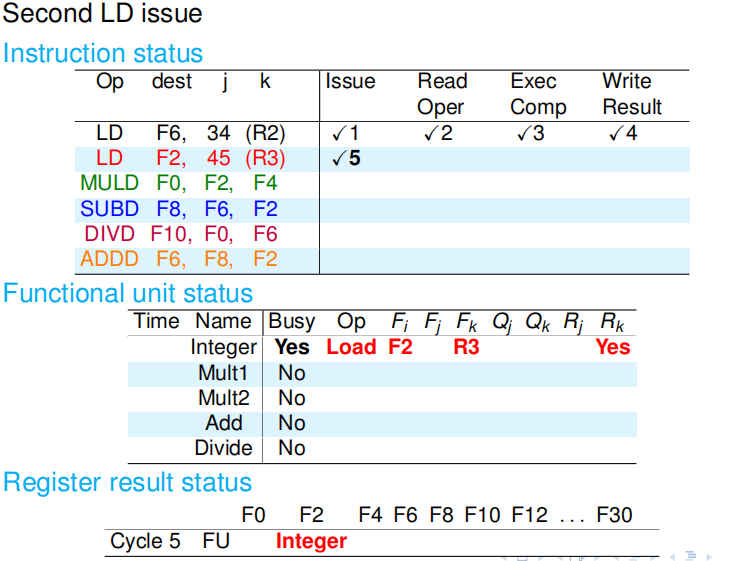
第五个周期:整数部件空闲,所以第二条 LD 终于可以发射了. 在周期结束时,LD 改写记分牌,并且改写寄存器状态. |
|
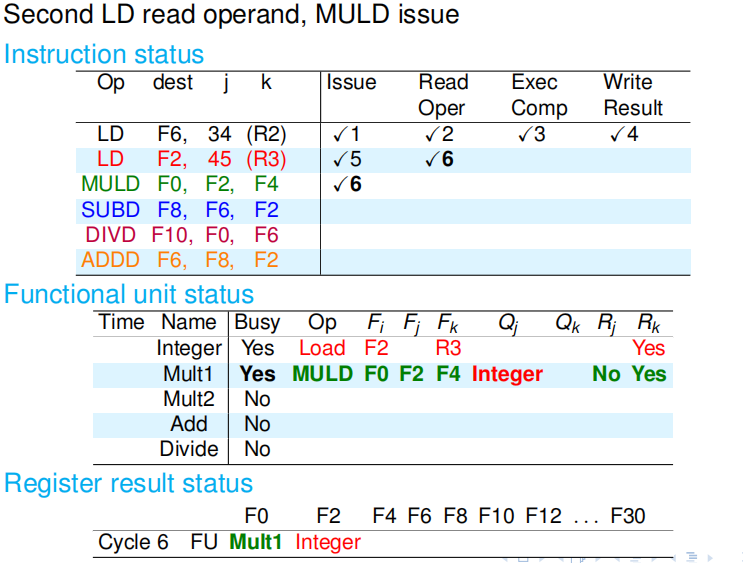
第六个周期:乘法部件有空闲,所以 MULD 顺利发射;LD 要读的寄存器的值都是最新的,所以可以读取. 周期结束时,LD 指令不会改写记分牌.据寄存器状态可知,源寄存器 F2 正要被整数部件改写,所以 MULD 要读的 F2 是过时的,因此记分牌中会打上标记,表示 MULD 指令还不能读 F2. 周期结束时,LD指令不会改写记分牌. |
|
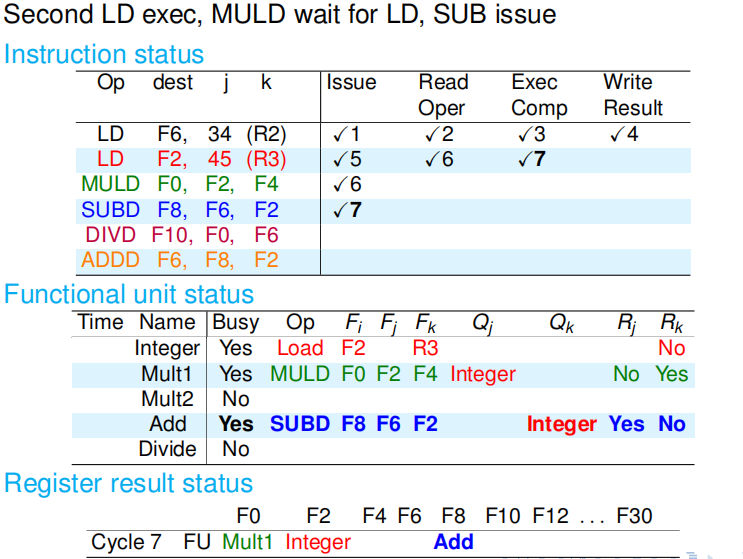
第七个周期:加法部件空闲,所以 SUBD 指令可以发射;MULD 因为记分牌告诉它它还不能读取 F2 ,所以卡在部件寄存器中,不能读数;LD 指令顺利执行. 周期结束时,SUBD 指令改写记分牌,根据寄存器状态可知,源寄存器 F2 要被整数部件改写,所以不能读,因此记分牌中标记 F2. 周期结束时,MULD 因为卡在部件寄存器中,所以没有任何动作. 周期结束时,LD 改写记分牌,主要是改写 Rk,以表明自己不再需要读寄存器 R3. |
|
第八个周期:因为除法部件空闲,所以 DIVD 可以发射;SUBD 和 MULD 指令因为 F2 寄存器还没准备好(看第七个周期的记分牌),所以这个周期卡在部件寄存器中;LD 顺利写回. 周期结束时,DIVD 改写记分牌,根据寄存器状态,源寄存器 F0 正要被乘法部件 1 改写,所以记分牌标记 F0,表面 F0 还不能读. 周期结束时,SUBD、MULD 还没有动作,但是关于这两条指令的记分牌内容出现变化了,具体看下一段. 周期结束时,LD 将数据写回寄存器堆,并且改写功能状态,具体工作是通知各个部件寄存器,F2 寄存器已经被改写好了,寄存器堆中的 F2 现在是最新值,经过 LD 的通知,SUBD、MULD 指令 R 信息就从 No 被改为 Yes ;并且解放寄存器状态,表明 F2 不再处于“即将被改写”的状态. |
|
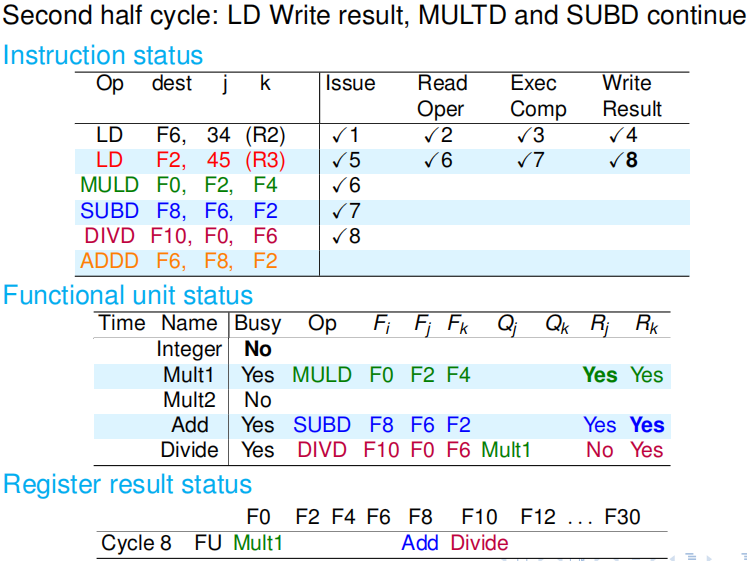
第九个周期:因为加法部件被 SUBD 指令占用,所以 ADDD 指令没办法发射;而 DIVD 指令因为要等到乘法部件 1 的结果,所以也没法读数;而 SUBD 和 MULD 两条指令因为上一周期 LD 写回完毕,所以这个周期可以读取所有它们需要的寄存器值,因此顺利渡过读数阶段. 周期结束时,功能状态和寄存器状态都没有变化.但是注意记分牌 Mult1 后面的 10 和 Add 后面的 2 ,这是在告诉我们从下一周期开始,乘法和加法将要开始各自的计算,其分别需要 10 个周期、2 个周期. |
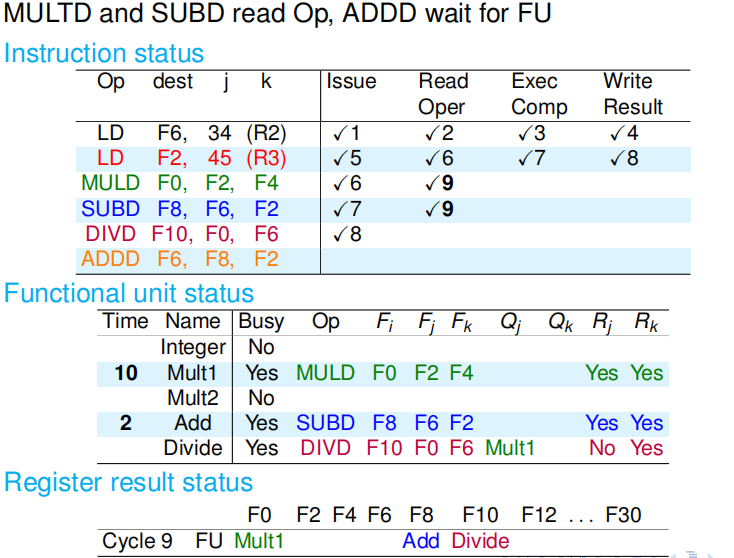
|
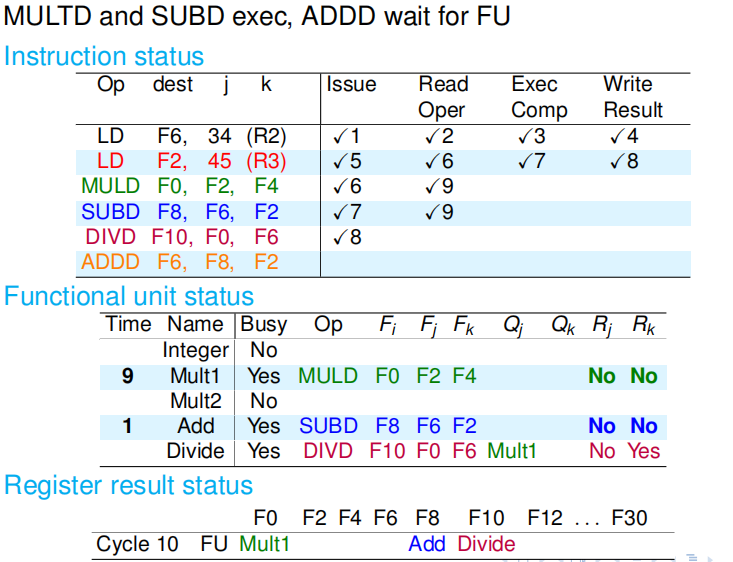
第十个周期:DVID 指令还在等待寄存器的新值;而乘法部件和加法部件完成了各自的第一个计算周期. 周期结束时,MULD 和 SUBD 修改记分牌,把 Rj 和 Rk 的内容置为 NO,表明自己不再需要读取寄存器.记分牌 Mult1 前面的 9 和 Add 前面的 1,表示乘法和加法还各自需要 9 个周期、1 个周期才能执行完毕. |
4.2. Tomasulo Algorithm | 托马斯路算法
-
Tomasulo 算法的优点:
-
Tomasulo 算法的缺点:
-
无法避免内存上的 WAW 与 WAR 冒险,只是通过保留站解决了寄存器上的 WAW 与 WAR 冒险.
-
TBD
-
-
Tomasulo 算法在循环场景中也有助于提升性能(我认为这是因为 Tomasulo 算法的优化不会),但是效果肯定没有直接循环展开的提升来的大.