1. Introduction to Memory Hierarchy | 导论
-
随机存取存储器(random access memory, RAM)
-
静态随机存取存储器(static RAM, SRAM):快、贵、数据"永久"保留直到断电.
-
动态随机存取存储器(dynamic RAM, DRAM):慢、便宜、需要定期"刷新".
-
-
局部性原则(principle of locality)
-
时间局部性(temporal locality):最近被访问过的数据可能在不久之后会被再次访问.
-
空间局部性(spatial locality):被访问过的数据的邻近数据在不久之后很可能被访问.
-
内存层次结构
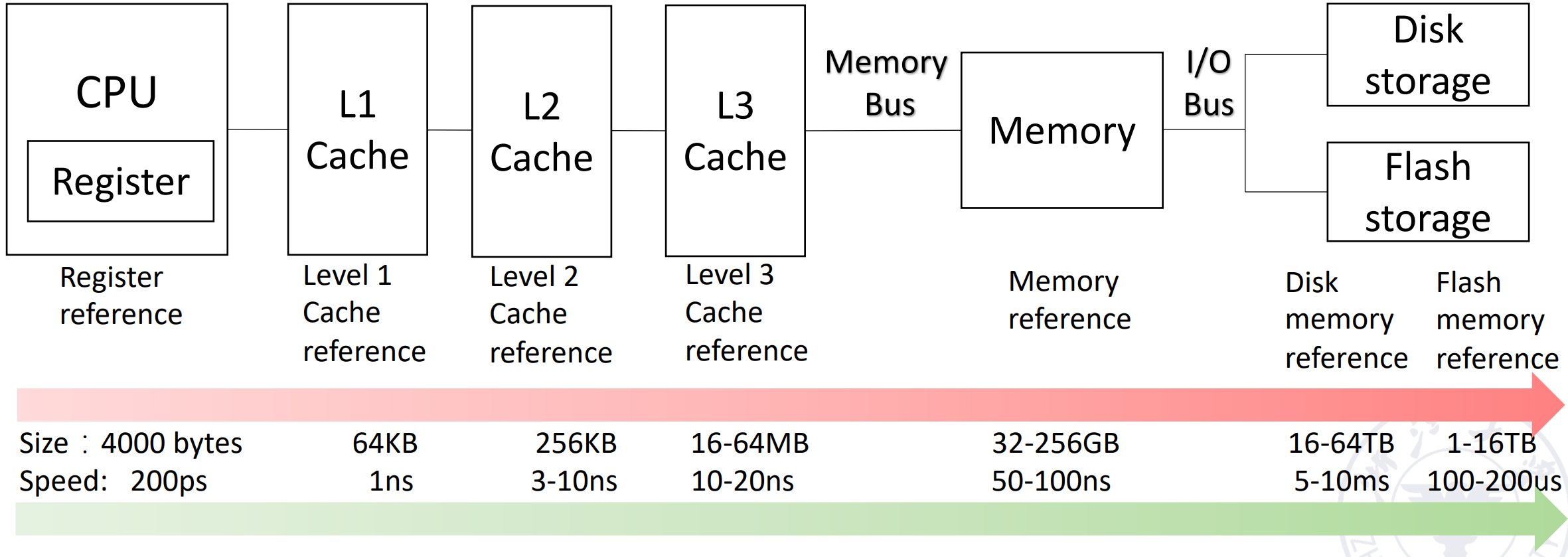
回顾:和 cache 相关的概念与名词

2. Four Questions for Memory Hierarchy Designers | 四个关键问题
-
内存设计者需要回答的四个问题:
-
Q1: Where can a block be placed in the upper level/main memory? (Block placement)
-
Q2: How is a block found if it is in the upper level/main memory? (Block identification)
-
Q3: Which block should be replaced on a Cache/main memory miss? (Block replacement)
-
Q4: What happens on a write? (Write strategy)
-
2.1. Block Placement | 块的放置
-
直接映射(direct mapped):块只能放在缓存中的一个位置.
-
全相联(fully associative):块可以放在缓存中的任意位置.
-
组相联(set associative):块可以在一个组里的任意位置,组里可以有若干块.
- 如果组中有 个块,则称为 -路组相联.一般来说,.
2.2. Block Identification | 块的标识
-
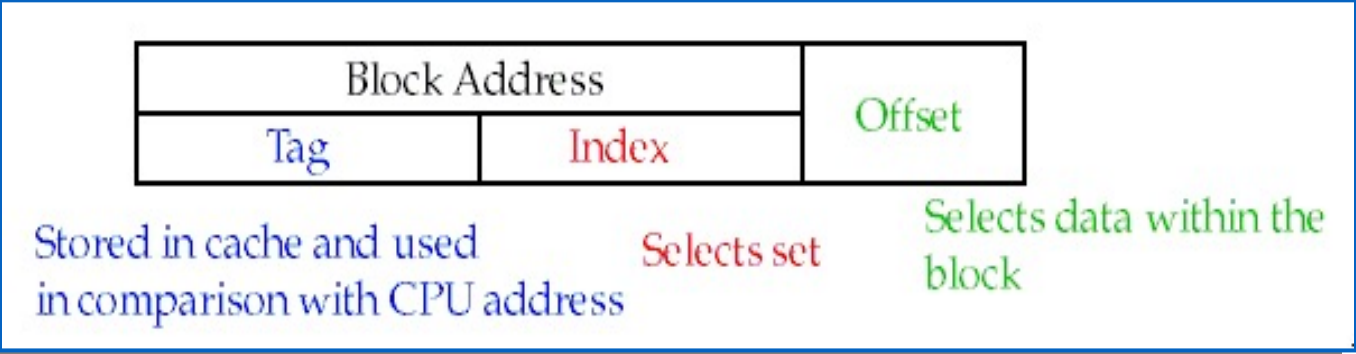
块的组成部分:
-
标签(tag):可用于辨别某个块是否是所需要的,这个搜索过程一般是并行执行的.
- 需要的 tag 位数 = 地址位数 - index 位数 - block offset 位数
-
索引(index):在直接映射/组相联中用于选择具体的块/组(在全相联中就不需要).
-
块偏移(block offset):用于在一个块中选择具体数据(定位到具体字节),不包含在块地址中.
-
2.3. Block Replacement | 块的替换
-
随机替换(random replacement):随机选择一个cache中的块并进行替换.
- 实现简单.也可以用一些伪随机数算法实现.
-
最近最少使用(Least-Recently Used, LRU):替换最近没有使用过的块——需要额外的位数来记录访问时间.
- 存在近似策略——使用 ref bit.
-
先进先出(First-In-First-Out, FIFO):选择最早进入cache的块进行替换.
- 算是一种 LRU 的近似策略.
2.4. Write Strategy | 写入策略
-
write through V.S. write back
-
写穿(write through):同时写入 cache 和下一级内存中.
-
优点:实现简单,数据一致性(data coherency) 好.
-
缺点:CPU 必须等待下一级内存写入完成才能执行下一步,称为 写停顿(write stall).
-
可以引入 写缓冲(write buffer) 来缓解这个问题.
-
可以引入二级缓存(L2)来进一步缓解写缓冲区也容易饱和的问题.
-
-
-
写回(write back):只写入到 cache 的块中,但是如果这个块要被移除 cache 则将数据写入到下一级内存中.
-
优点:速度快、使用更少的内存带宽.
-
需要引入一个 脏位(dirty bit) 来标记块是否有被修改过.
-
-
-
块未命中时(write miss)的写入策略
-
写分配(write allocate)(对应 write back 策略):当cache未命中时,先从下一级内存把块加载到 cache中.
-
非写分配(no-write allocate, write around)(对应 write through 策略):不让 write miss 影响到 cache,而是直接写入到下一级内存中.
-
?
3. Cache Performance Measures | 缓存性能指标
3.1. CPU Execution Time | CPU 执行时间
- CPU 执行时间(考虑 cache miss 导致的 memory stall):
3.2. Average Memory Access Time | 平均内存访问时间
- 平均内存访问时间(average memory access time, AMAT):
- 分开考虑 Inst. & Data 内存的情况:
- 将AMAT应用到CPU Time的计算中(将指令分成 ALU 指令和内存访问相关指令两个部分):
4. Improve DRAM Performance | 提升DRAM性能
5. Improve Cache Performance | 提升缓存性能
- 如何提升 cache 的性能?就是降低 AMAT.可以从 AMAT 的计算公式入手考虑.
Tip
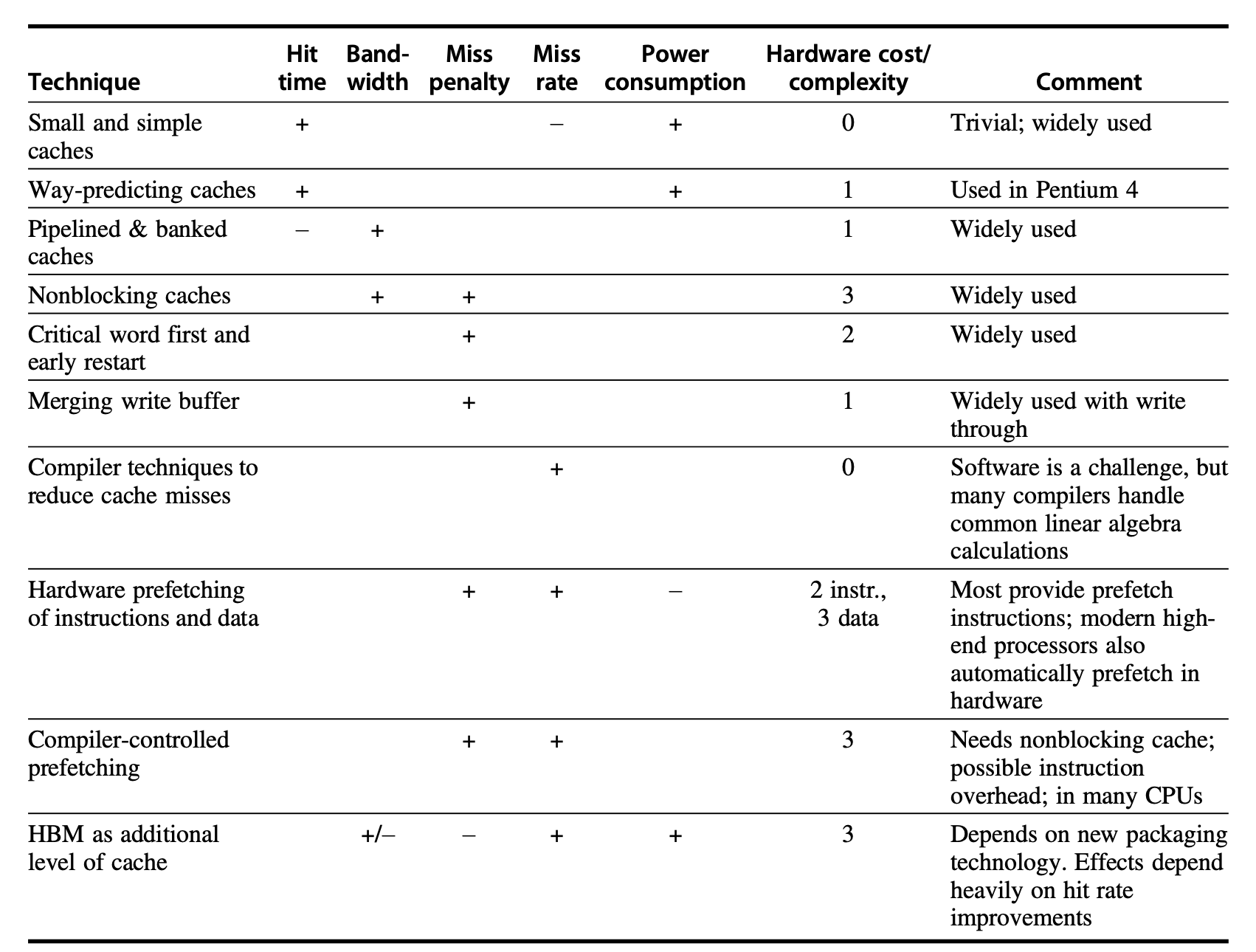
5.1. Reduce Hit Time | 减少命中时间
5.1.1. Small and Simple Caches | 使用小且简单的缓存
-
方法:使用小型、直接映射的cache;因为结构越简单就意味着hit时速度越快,直接映射不需要组内查找.
-
优点:简化结构 减少 hit time;减少功耗.
-
缺点:增加 miss rate.
-
结论:广泛使用,一般用在 L1 cache.
5.1.2. Way Prediction | 路预测
-
方法:路预测(way-prediction) 通过在cache中保留额外的位(称为 predictor bit)来"预测"每个组中访问的路.实际上 predictor bit 存储的就是该组上一次访问的路.
-
如果hit,只需要一个时钟周期,因为不需要进行查找.
-
如果miss,更新predictor bit并继续判断,这会带来一个额外的时钟周期,直到最终hit.
-
-
优点:减少 hit time;减少功耗.
-
缺点:加大了实现流水线化 cache 的难度.
5.1.3. Avoiding Address Translation during Indexing | 减少地址转换
-
问题:在计算机中尝尝需要使用虚拟地址来访问内存,然而 cache 是基于物理地址的,需要page table进行转换——相当于每次访问都需要进行两次内存操作.
-
方法一:使用虚拟地址来索引 cache(virtuall addressed cache)?
- 会导致 同义词问题(synonym problem):两个虚拟地址可能映射到同一物理地址,从而导致同一个物理块在 cache 中有多个副本.进而导致数据不一致问题.
-
方法二:使用计组中讲到过的 TLB.
5.1.4. Trace Caches
5.2. Increase Bandwidth
5.2.1. Pipelined Caches
5.2.2. Multibanked Caches
5.2.3. Nonblocking Caches
5.3. Reduce Miss Penalty
5.3.1. Multi-level Caches
5.3.2. Giving Priority to Read Misses over Writes
5.3.3. Critical Word First & Early Restart
5.3.4. Merging Write Buffer
5.3.5. Victim Caches | 受害者缓存
5.4. Reduce Miss Rate
-
cache miss 的来源:
-
强制(compulsory)(也称为 冷启动失效 (cold-start misses)):在一开始访问cache必定出现miss,因为块必须先被加载到cache中.
-
容量(capacity):在程序执行的过程中,cache无法包含所有需要的块,于是不得不抛弃一些块,但之后可能又需要这些块,从而发生miss.
- 除非增大cache容量,否则这一问题无法解决(不在本小节的讨论范围内).
-
冲突(conflict):对于组相联 / 直接映射而言,由于多个数据块映射到相同的组上,导致较早存入的数据被替换,导致后续又需要时发生miss.
-
一致性(coherency):针对多核处理器导致的cache一致性缺失,不在目前的讨论范围内.
-
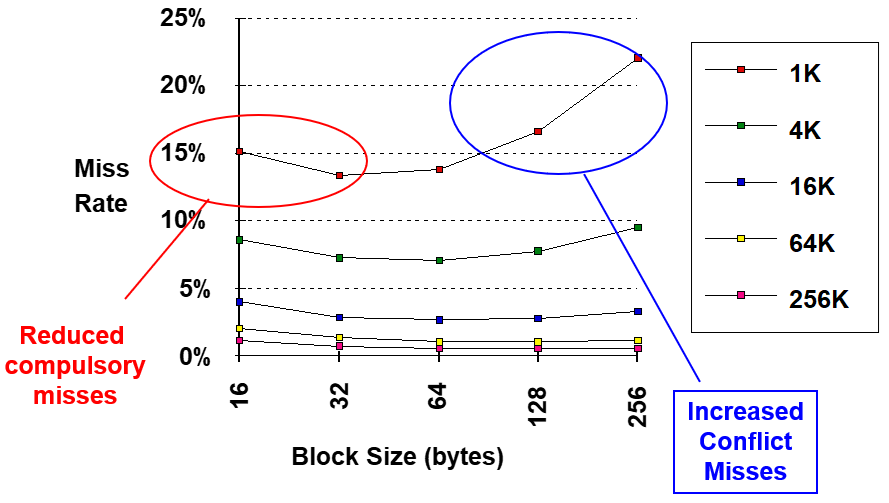
5.4.1. Larger Block Size | 增加块大小
-
优点:减少 compulsory miss.
-
缺点:
-
增加 miss penalty.
-
增加 conflict miss.
-
增加 capacity miss,特别是对于小 cache.
-
-
结论:优化曲线呈 U 形,存在 trade-off.
5.4.2. Larger Caches | 增加缓存大小
-
优点:减少 capacity miss.
-
缺点:
-
增加 hit time.
-
增加成本和功率.
-
-
在芯片高速缓存的优化中一般不考虑这种方法.
5.4.3. Higher Associativity | 增加相联度
-
方法:就是增加" 路组相联"里的 .
-
优点:减少 miss rate,但也取决于具体的访问序列.
-
缺点:增加 hit time.
-
经验:8路组相联降低miss rate的效果近乎等价于全相联——再提高相联度的效果不明显.
-
结论:对于clock rate较高的情况下,不建议提升相联度;但在miss penalty较大的情况下,可以考虑提升相联度.
5.4.4. Compiler Optimizations
5.4.5. Way Prediction and Pseudo-Associative Cache
5.5. Reduce Miss Penalty/Rate via Parallelization
5.5.1. Hardware Prefetching of Inst. and Data | 硬件预取
5.5.2. Compiler-controlled Prefetch | 编译器控制的预取
5.6. Using HBM to extend the memory hierarchy
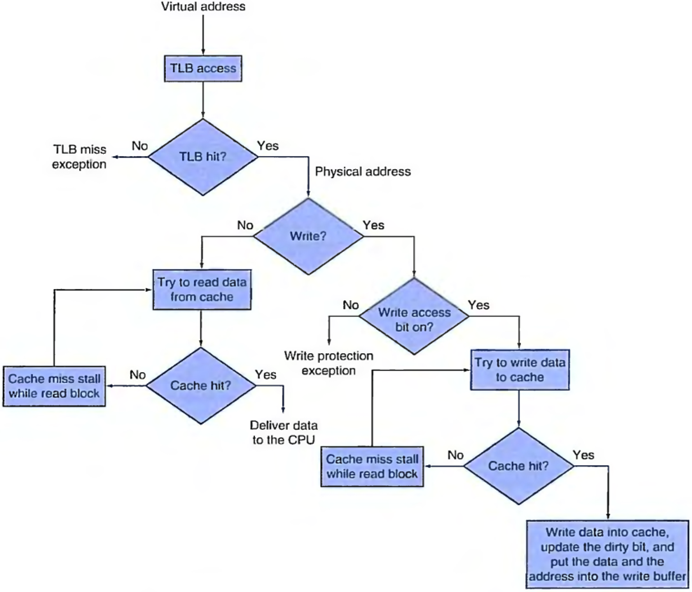
cache 流程总结